有效避免神经网络过拟合的六种实用技术方案
神经网络因其强大的拟合能力,经常会遇到过拟合的情况。过拟合通常发生在模型参数过多、结构过于复杂,以至于试图去学习训练数据中包含噪声的“趋势”。这类模型的预测结果往往不够精确,因为它所捕捉的并非数据的真实分布规律。
判断过拟合的典型依据是:模型在已知的训练集上表现优异,但在未见过的测试集上性能显著下降。机器学习的核心目标是使模型能够从训练集泛化到整个问题领域的任意数据,从而对未知数据做出可靠预测。
基于此,本文将详细阐述六种在神经网络训练中缓解过拟合的实用技术方案。
一、简化模型
应对过拟合的首要步骤是降低模型复杂度。具体而言,可以通过移除网络层或减少各层神经元数量来缩小网络规模。在此过程中,仔细计算神经网络各层的输入与输出维度至关重要。尽管目前对于移除多少层或缩减至何种规模没有统一标准,但当观察到模型出现过拟合迹象时,尝试减小其规模通常是一个有效的起点。
二、早停
早停是一种在迭代式训练 (如梯度下降) 过程中应用的正则化策略。由于几乎所有神经网络都依赖梯度下降进行参数学习,因此早停是一种具有普适性的技术。在训练迭代中,模型会不断更新参数以更好地拟合训练数据。在初始阶段,这种更新通常也会带来测试集性能的提升。然而,超过某个临界点后,持续优化训练数据的拟合程度反而会导致泛化误差 (测试集误差) 的上升。早停规则的作用就是确定模型在开始过拟合之前,能够进行的最大迭代次数。
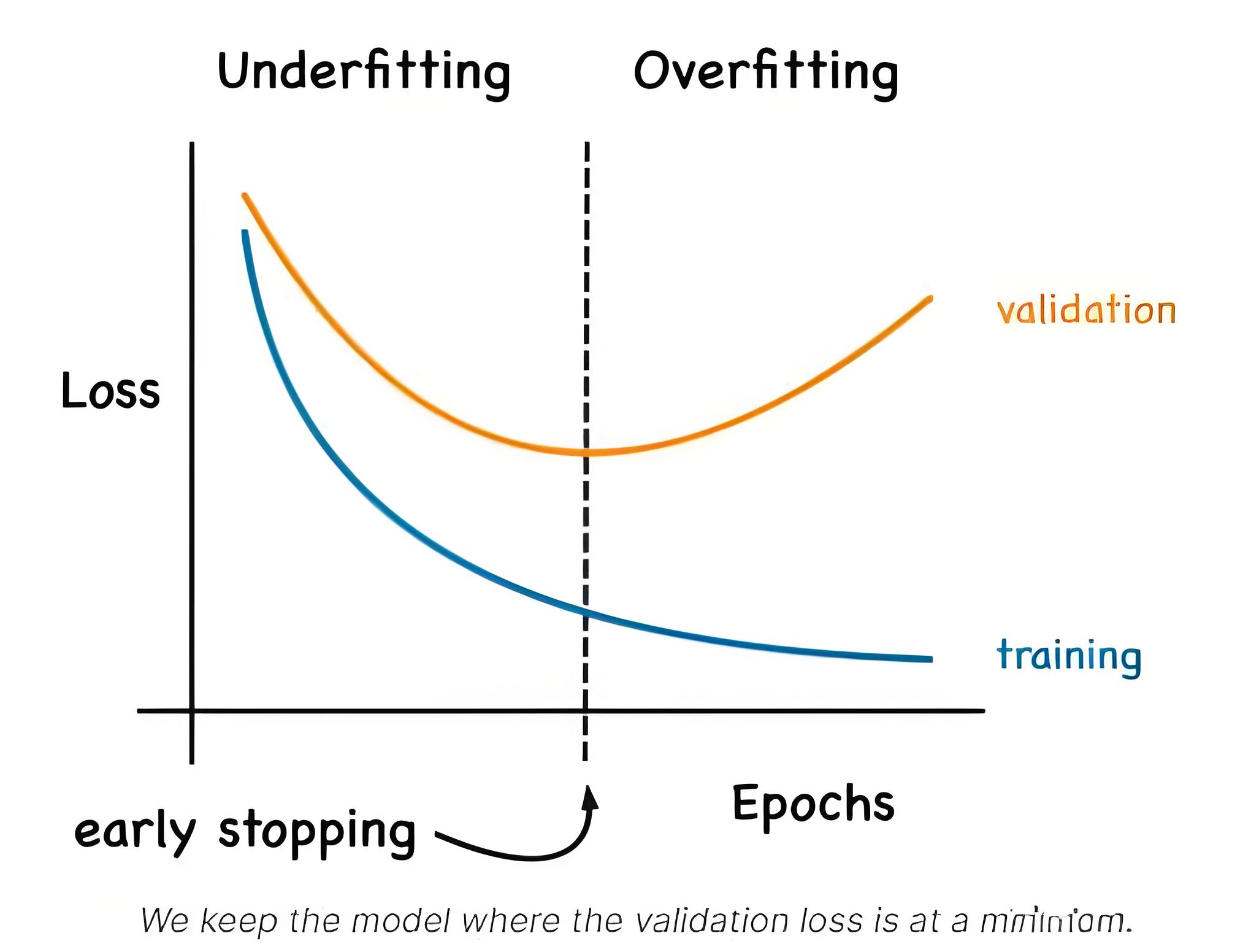
如上图所示,经过若干次迭代后,即便训练误差持续降低,测试误差却已开始回升,此时便是停止训练的最佳时机。
三、使用数据增强
在神经网络训练中,数据增强特指通过特定变换增加数据集的规模,对于图像任务而言,即增加训练图像的数量。常用的图像增强技术包括:翻转 (水平/垂直)、平移、旋转、缩放、亮度调整、添加噪声等。

如上图所示,通过数据增强可以从单张原始图像生成多幅相似但又不完全相同的样本。这一过程有效扩大了数据集规模,从而缓解过拟合。其核心逻辑在于:随着数据量的增加,模型难以记住所有样本的细节,被迫学习数据中更为普遍的、具有代表性的特征,进而实现更好的泛化。
四、使用正则化
正则化是另一种降低模型复杂度的有效手段,其核心思想是在模型的损失函数中引入一个惩罚项。最主流的正则化技术包括 L1 正则化和 L2 正则化:
- L1 正则化:其惩罚项旨在最小化权重参数的绝对值之和。公式如下:
- L2 正则化:其惩罚项旨在最小化权重参数的平方和。公式如下:
以下表格对比了两种正则化方法的主要特点:
| L1 正则化 | L2 正则化 |
|---|---|
| 惩罚项为权重绝对值的总和 | 惩罚项为权重平方值的总和 |
| 倾向于生成简单、可解释的模型 (权重稀疏) | 有助于学习复杂的数据模式 (权重普遍较小) |
| 对极端值 (离群点) 的敏感性较低 | 对极端值 (离群点) 的敏感性较高 |
L1 与 L2 正则化对比
至于选择哪种正则化方法更有利于避免过拟合,答案是“视情况而定”:
- 当数据模式复杂,难以用简单模型精确建模时,L2 正则化通常是更好的选择,因为它允许模型学习更丰富的内在规律。
- 当数据模式相对简单,有望被精确建模时,L1 正则化可能更合适,因为它能产生稀疏权重,增强模型解释性。
在我处理的大多数计算机视觉问题中,L2 正则化 (常称为权重衰减) 往往能带来更稳定的结果。不过,L1 正则化在抗干扰性 (对离群值不敏感) 方面的优势也不容忽视。因此,最终选择应基于具体问题的特性和数据特点。
五、使用丢弃法 (Dropout)
丢弃法是一种直接作用于神经网络结构的正则化技术。与 L1、L2 正则化通过修改损失函数来实现不同,丢弃法在训练过程中随机“丢弃”(即暂时失效) 一部分神经元。在每一次训练迭代中,被丢弃的神经元集合都是随机选择的。这种机制相当于每次迭代都在训练一个结构略有不同的“子网络”。由于不同的子网络可能会以不同方式过拟合,丢弃法通过平均这些子网络的预测效果,能够有效降低整体模型的过拟合风险。
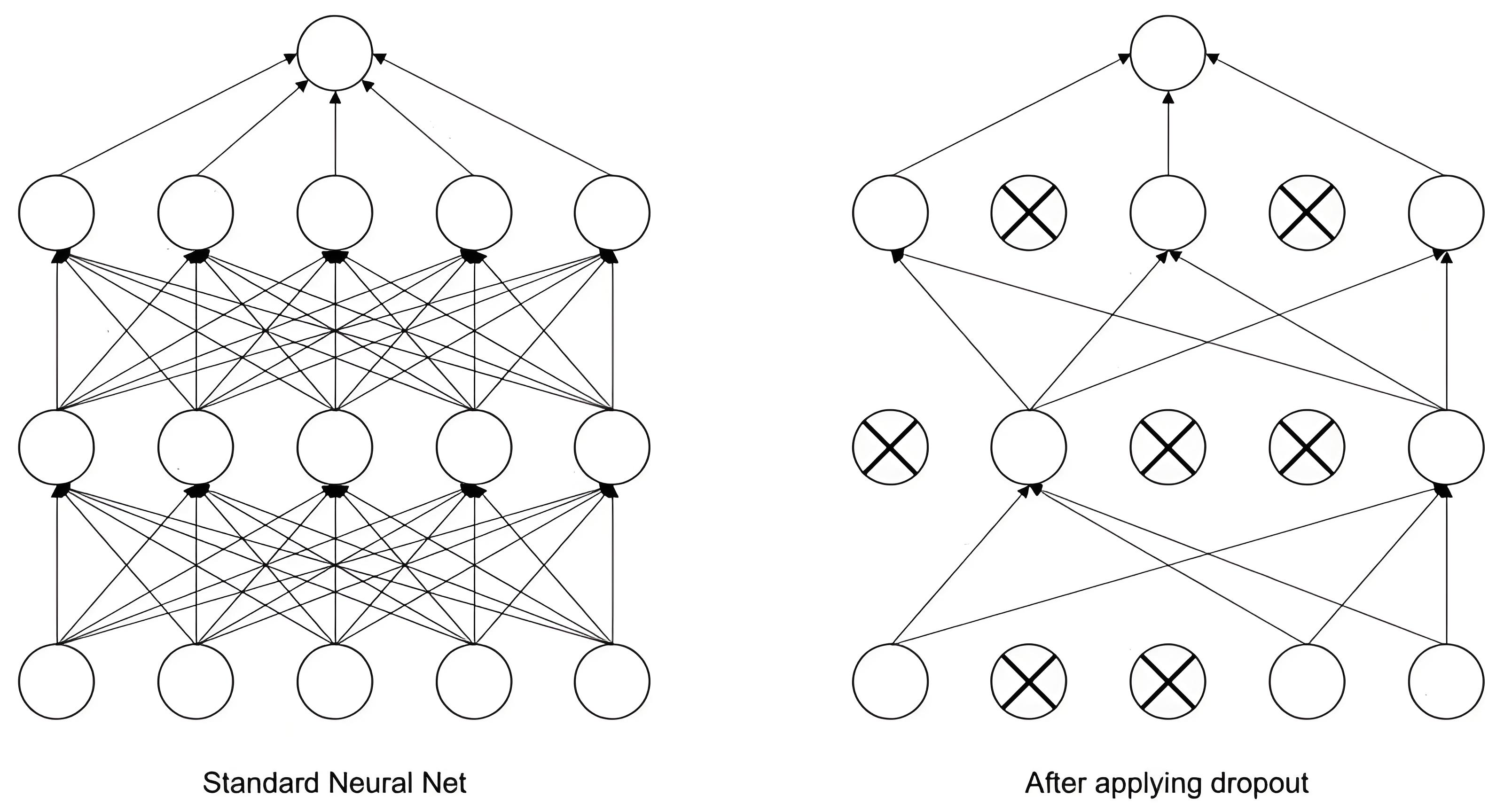
如上图所示,丢弃法在训练过程中随机地使部分神经元失活。实践证明,该技术在多种任务上均能有效减少过拟合,包括图像分类、图像分割、词嵌入学习以及语义匹配等。
六、批归一化 (Batch Normalization)
核心思想是为了解决内部协变量偏移 (Internal Covariate Shift) 问题。在神经网络训练过程中,每一层的参数都在不断更新。这意味着,对于网络中的任意一层而言,其输入数据的分布会随着前一层参数的变化而持续改变。这就好比后一层面对的输入是一个“移动的靶子”,需要不断适应新的数据分布,这无疑增加了训练的难度,不仅要求更谨慎地设置学习率,还会导致训练速度变慢。
批归一化是如何解决这一问题的呢?方法其实非常简单且有效:对每一层的输入 (或激活函数的输出) 进行标准化处理,使其均值变为 0,方差变为 1。具体而言,它会在一个小批量 (Mini-batch) 的数据上计算均值和方差,然后利用这些统计量来标准化该批次的数据。
批归一化为何具有正则化效果?这可以说是 BN 带来的一个“意外之喜”。因为在训练阶段,BN 所使用的均值和方差是基于当前小批量数据计算得出的,而这种小批量统计量本身是带有噪声的估计值。这使得每一层的输出并非固定不变,而是会随着不同批次数据的变化而产生细微波动。这种“噪声”与 Dropout 的效果类似,能够迫使后续神经元不过度依赖前面任何一个神经元的精确激活值,从而带来了轻微的正则化效果,有助于降低模型的过拟合风险。
结论
综上所述,本文首先解释了过拟合的概念及其在神经网络训练中普遍存在的原因,随后详细介绍了五种最常用的缓解策略:简化模型、早停、数据增强、正则化 (L1/L2) 以及丢弃法。这些技术从不同角度 (模型结构、训练过程、数据规模、损失函数) 入手,为有效控制过拟合、提升模型泛化能力提供了全面的解决方案。