Transformer 的整体结构
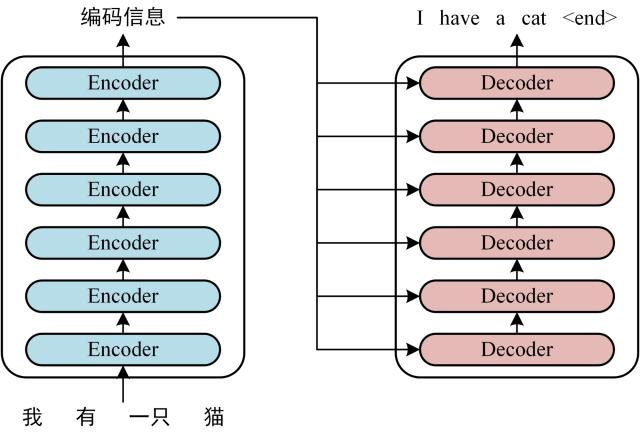
Transformer 的工作流程大体如下:
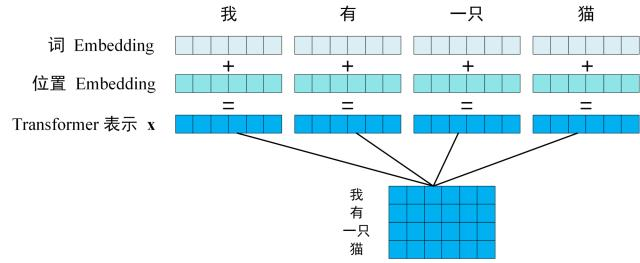
- 获取输入句子中每个单词的表示向量 X, 它由单词的 Embedding 和单词位置的 Embedding 相加得到. 如下图所示, 每一行是一个单词的表示向量.
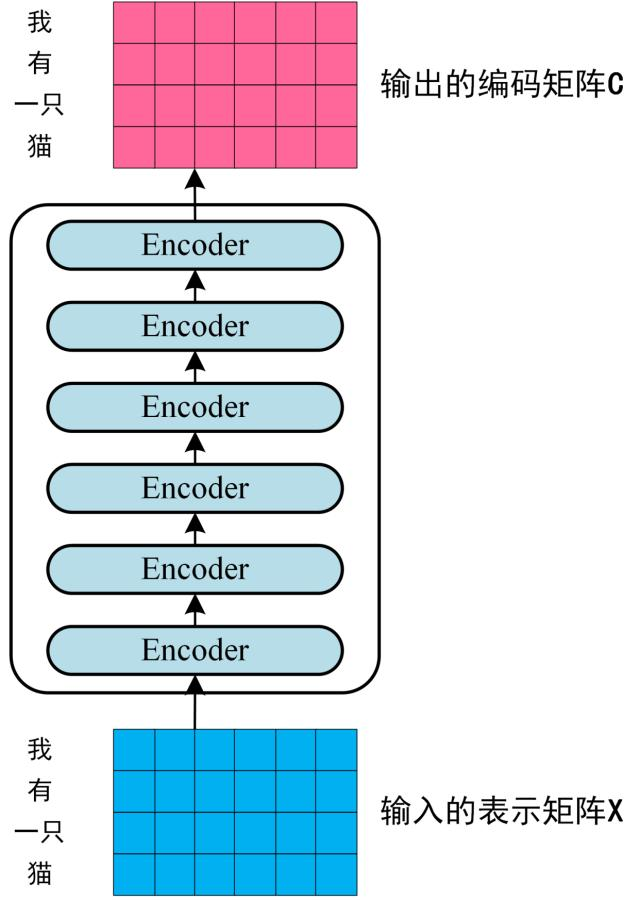
- 将得到的单词表示向量矩阵传入 Encoder, 经过 6 个 Encoder block 后得到句子所有单词的编码信息矩阵 C.
如下图所示, 单词向量矩阵用 表示, 其中 是句子中单词的个数, 是表示向量的维度 (论文中 ).
每个 Encoder block 输出矩阵的维度与输入是一致的.
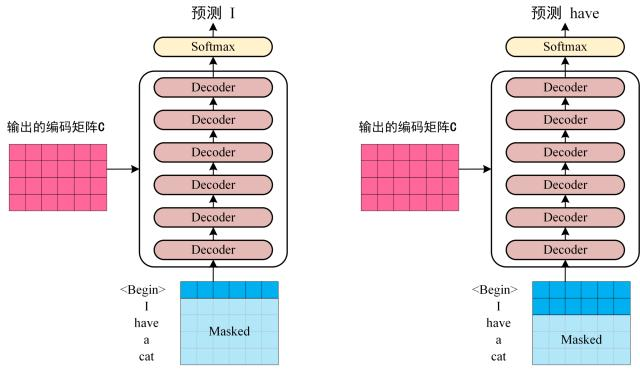
- 将编码信息矩阵 C 传入 Decoder 中, Decoder 会依次根据当前翻译过的 个单词翻译下一个单词 .
如下图所示, 在翻译到单词 时, 需要将 及之后的单词 Mask 掉.
将 Transformer 应用到翻译场景的动效.
![]()
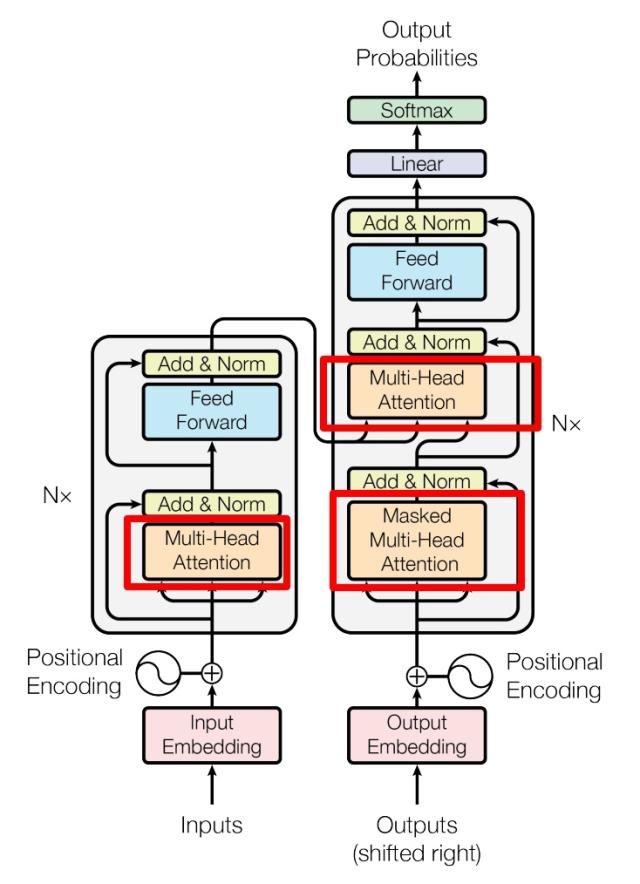
Transformer 的内部结构
这是 Transformer 细化的内部结构图, 左侧为 Encoder block, 右侧为 Decoder block. 红色圈中的部分为 Multi-Head Attention, 它由多个 Self-Attention 组成. 可以看到 Encoder block 包含一个 Multi-Head Attention, 而 Decoder block 包含两个, 其中一个用到 Masked. Multi-Head Attention 上方还包括一个 Add & Norm 层, Add 表示残差连接 (Residual Connection), 用于防止网络退化, Norm 表示 Layer Normalization.
Transformer 的输入
位置 Embedding 计算公式
Self-Attention (自注意力机制)
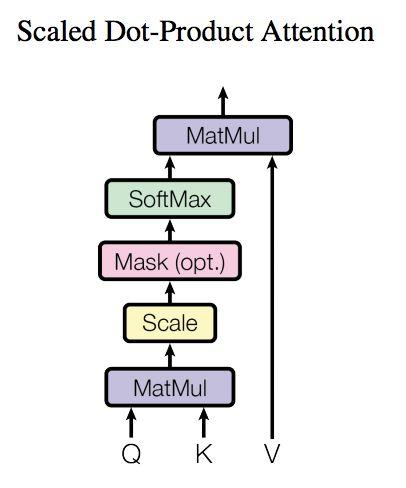
Self-Attention 结构如下图所示, 在计算的时候要用到矩阵 Q(查询), K(键值), V(值).
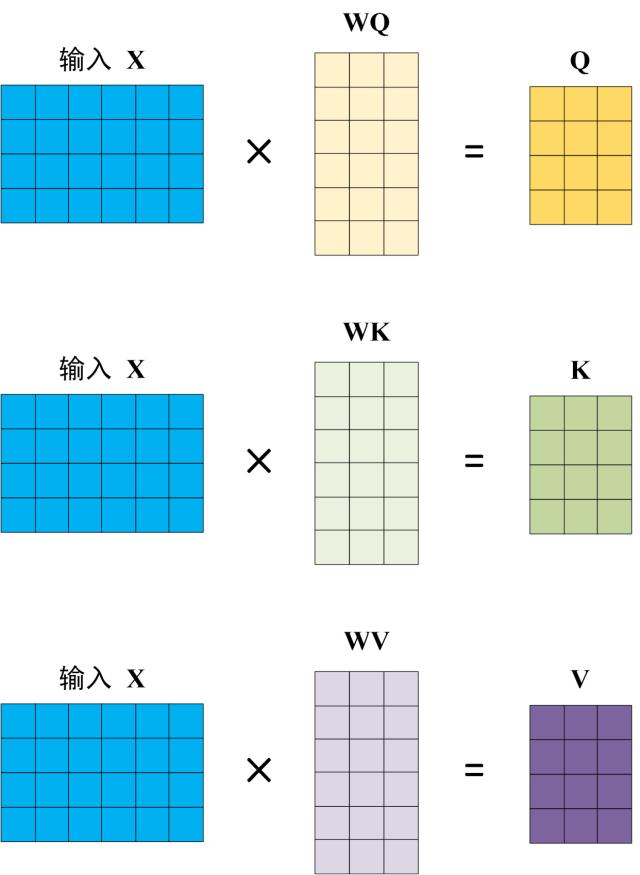
在实际计算中, Self-Attention 的输入是单词表示向量矩阵 X, 或上一个 Encoder block 的输出, 而 Q, K, V 是通过输入线性变换得到的. 计算过程如下图所示, 注意 X, Q, K, V 的每一行都表示一个单词.
Multi-Head Attention
Multi-Head Attention 由多个 Self-Attention 组合而成, 结构如下.
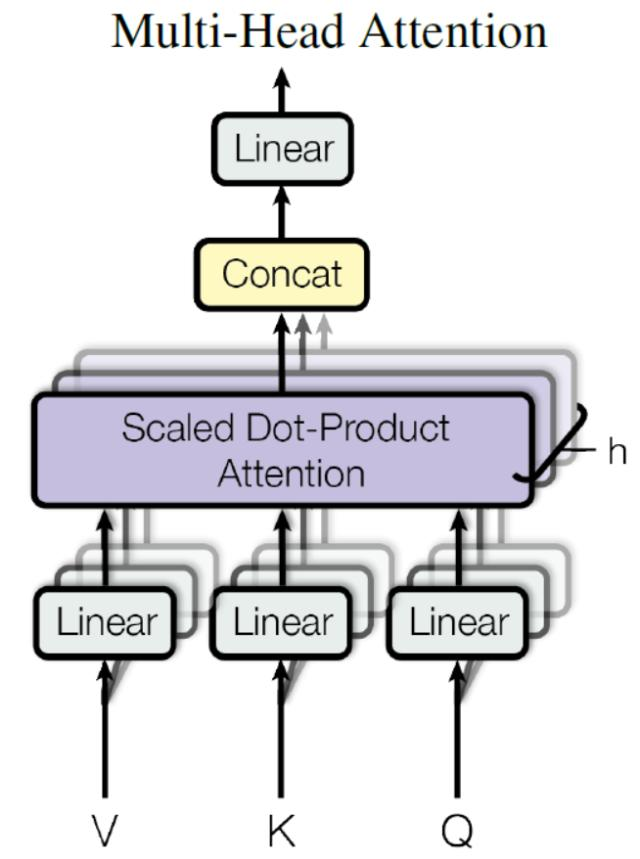
将输入 X 分别传递到 h 个不同的 Self-Attention 中, 计算得到 h 个输出矩阵 Z, 将它们 Concat 在一起, 传入 Linear 层, 最终得到 Multi-Head Attention 的输出 Z.
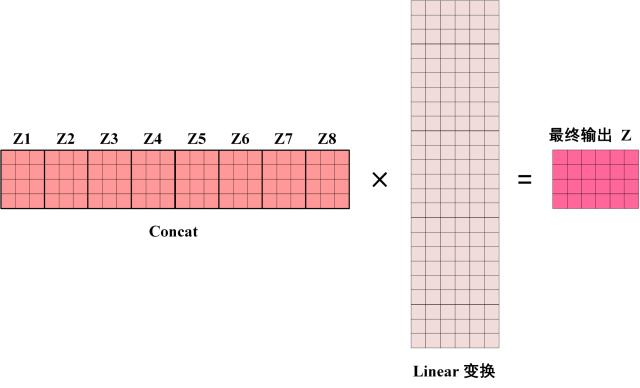
通过控制 Linear 层的列数, 来确保 Multi-Head Attention 输出的矩阵 Z 与其输入的矩阵 X 的维度是一样的.