导读 本文将介绍快手的推荐系统,精排推荐模型上的一系列工作,包括 CTR 模型、参数个性化网络、多 domain 多任务学习框架、短期行为序列建模、长期行为序列建模、千亿特征万亿参数模型等。
分享嘉宾|牛亚男 快手 资深推荐算法工程师
编辑整理|陈惠宇 中科院自动化所
出品社区|DataFun
01快手推荐系统 1. 快手推荐系统简介
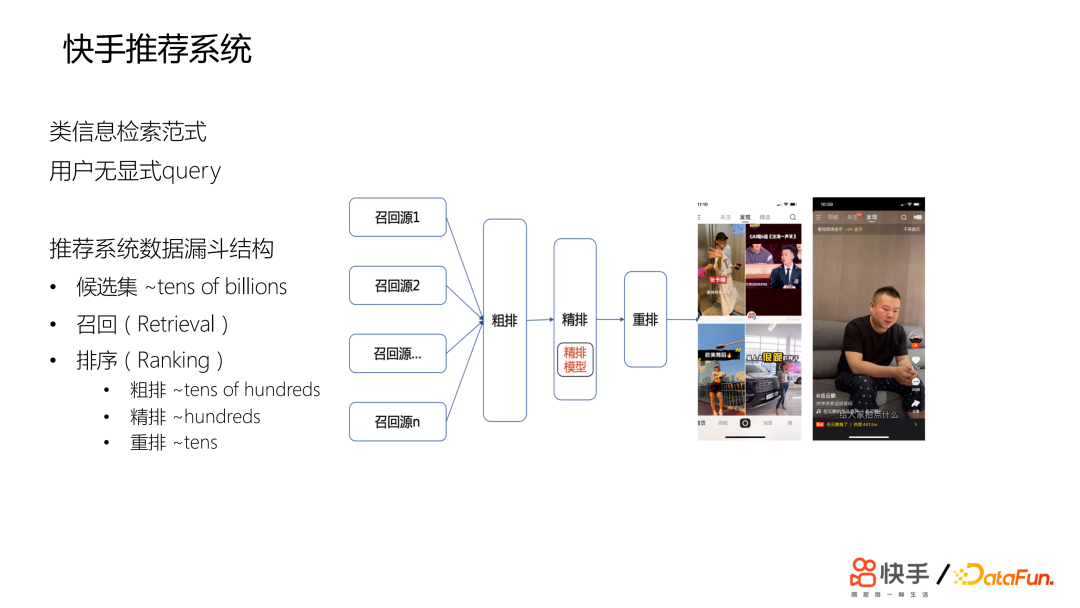
快手的推荐系统是一种类信息检索的方式,类似于搜索引擎,但显著的区别在于推荐系统没有显式的 query,这为推荐效果的判断和 debug 过程带来一定的困难。训练数据主要基于用户的行为日志和用户的反馈。整个推荐系统的结构类似于数据漏斗的结构。在候选集也就是召回池中,有着百亿数据的规模,通过数据召回将会有数千个视频提供给粗排模型。经过粗排的打分和重排后,会提供前几百个数据给精排模型,经过精排模型的打分和处理后将会有几十个数据提供给重排,经过重排最终呈现给用户。2. 快手推荐系统特点
快手推荐系统存在以下特点:
- 数据量大:有数亿用户、数百亿短视频。
- 用户行为数据差异大:用户的活跃度差异性较大。
- 用户内容更丰富,用户兴趣广泛且多变,用户交互类型多,场景复杂。
下面是主要的用户交互体验:
- 主站发现页:内外双流,通过双阶段:点击、滑动筛选用户感兴趣的视频
- 主站精选:单列交互体验
- 极速版发现页:纯单列,鼓励用户产生更多交互
- 关注页:基于 sis 用户社交关系的 tab 页
- 同城页:基于 lbs 发掘用户同城短视频、直播服务
- 直播场景:普通直播或电商直播
难点和挑战在于如何对用户兴趣进行精准的建模。
02
CTR 模型
1. CTR 模型概述
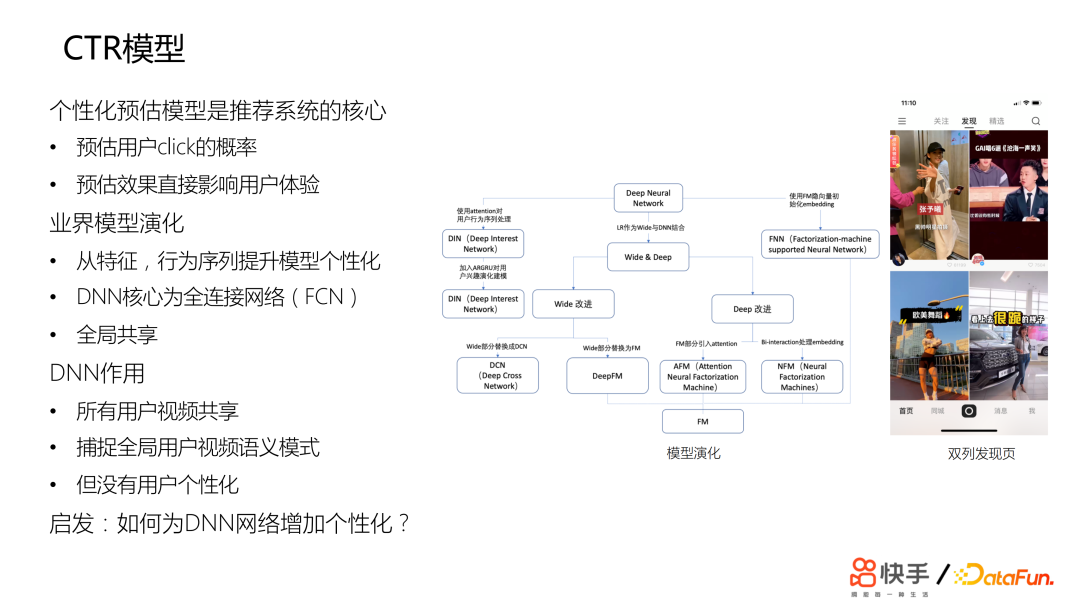
个性化预估是推荐系统的核心部分。CTR 模型的主要应用场景是在主站的双列的交互体验。用户的交互是双阶段的,首先用户先要点击,然后再根据短视频的内容进行反馈。所以点击会直接影响用户的体验。业界的模型演化的目标是提升模型的表达能力。对于推荐系统是提升模型的个性化成度。从特征、行为序列层面来提升,能够提升模型的特征交叉能力;行为序列建模可以提升模型的表达能力。精排模型的 backbone 普遍使用的是全连接的网络,全局共享。全连接网络的作用在于捕捉全局用户和短视频的喜好模式,但是其显著问题在于没有个性化。这带来一个启发:如何为 DNN 网络提升个性化?2. 提升模型个性化尝试方案
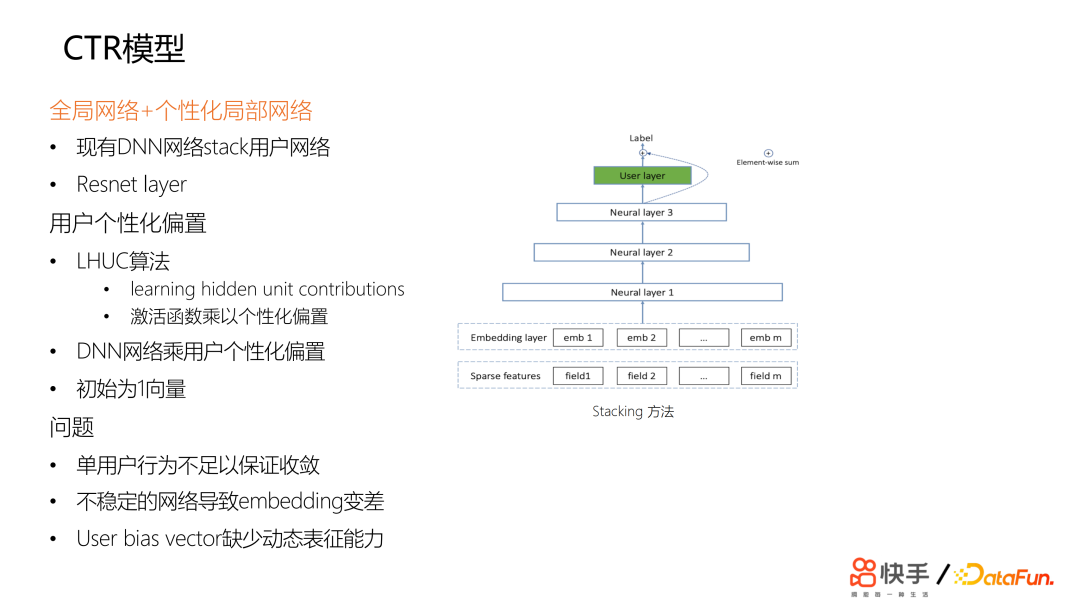
针对提升 DNN 模型个性化的模板,进行了许多尝试。首先,尝试了全局网络+个性化局部网络的方法。受 ResNet 启发,设计用 stacking的方法,给每个用户一个 specific 的网络。另一个尝试方案称为用户个性化偏置,这个方案受 LHUC 算法的启发,这个算法来源于语音识别,算法的核心思想是每一层网络的激活函数都要乘以个性化偏置,个性化偏置项是与用户相关的。每个用户都有 user bias vector。我们在这两套方案上做了许多尝试,但并没有获得显著收益。后续分析原因总结为以下三点:
- 首先,这两个方案都是相当于给每个用户加了非常宽的 user ID 特征,需要用户非常多的行为才会使其收敛;
- 其次,不稳定的网络会导致 Embedding 效果变差,由于业务场景下短视频的冷启动问题非常严重,Embedding 的质量至关重要;
- 此外,这两种方案缺少足够的动态表达表征能力,因为 User ID 向量是一个 static 的表征,需要用户行为来让它产生动态表达能力。
3. PPNet(Parameter Personalized Net)
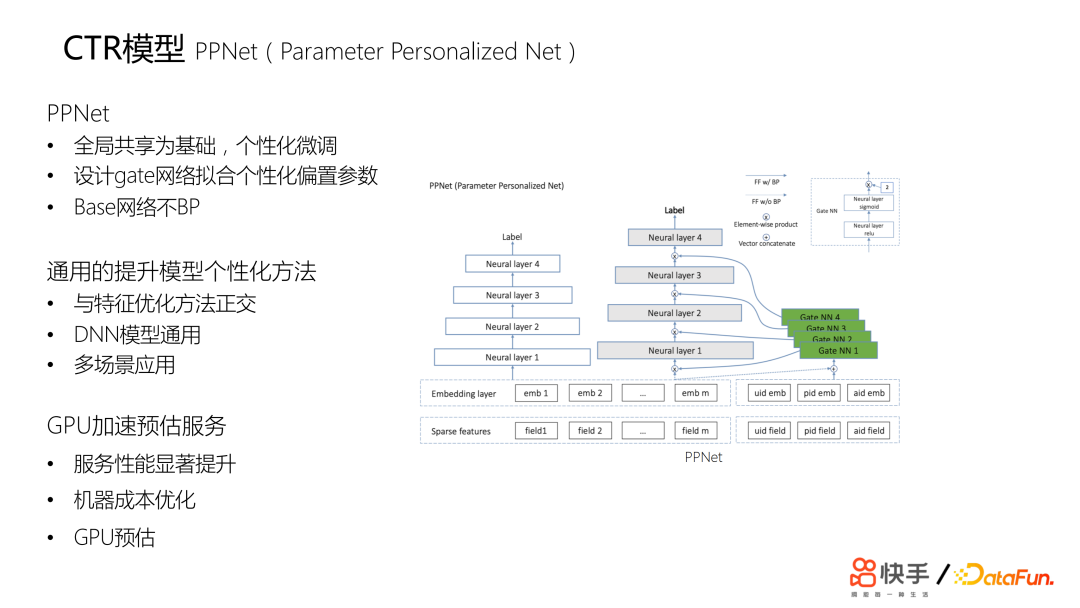
PPNet 是在原有基础上设计的最终方案,称之为参数个性化网络。模型结构参考下图。模型分为两部分,左边白色的这一部分是 base 模型,base 模型的意义在于保证原来 embedding 进行收敛。右边是PPNet 部分,灰色部分还是全局共享的,但是会在包括输入层在内的每一层,设计一个与用户和短视频相关的 gate 网络,gate 网络输入包括 embedding layer 和表征 ID。对于每条样本都可以产生一个不同的 DNN 网络。这个方案起到了非常大的提升效果,在新活跃用户上取得了全年最大的一次留存提升。PPNet 提供了一个比较通用的提升模型个性化的方案,它与特征优化的方案是正交的,并且即插即用的特性使其比较通用,应用场景广阔。后续配合工程进行优化,把线上预估服务从 CPU 迁移到了 GPU,做到了服务性能的显著提升,机器成本也做了优化,线上使用 GPU 进行预估。03
多 domain 多任务学习框架
1. 业务背景
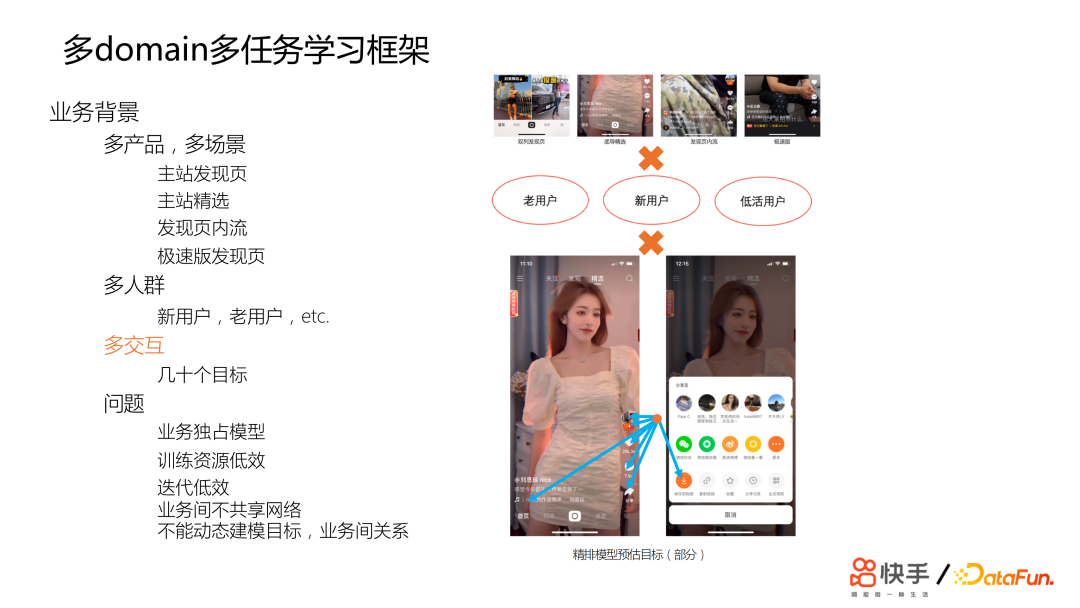
从 2019 年快手开始注重单列的交互体验,由于需要对所有的推荐产品做支撑,业务场景是多产品、多场景、跨人群、多预估目标的。如果每个业务或者人群细分独占一个模型,可能要训练非常多的模型,导致训练效率低;并且不同模型的优化无法共享,导致迭代效率非常低;同时我们也希望能够让不同业务之间的数据互相提升。

2. 挑战说首先是在不同业务场景下,交互样本目标、特征语义、embedding 分布均存在差异。不同目标在不同业务下的重要性也是不一样的。针对这些挑战,我们设计了多 domain 多任务的算法框架。3. 多 domain 多任务的算法框架

首先在语义层面进行对齐。其次对 embedding 空间对齐:我们认为在不同业务下,embedding 的空间分布存在差异。设计了一个gate网络来直接学习这种映射关系。把当前用户来自于不同业务的差异作为特征来学习一个映射网络,然后直接对输入层进行映射。下一步是特征重要性对齐:一些特征在不同业务下的重要性是不一样的。例如 Click 模型在双列产品上非常重要,但是在极速版就不太重要。针对不同的业务用户视频来学习特征级别的重要性。最后,个性化目标 MMoE,在 MMoE 的基础上动态建模目标之间的关系,在 task tower 针对不同的业务不同用户添加一些个性化偏置项。04
短期行为序列建模
1. 业务背景
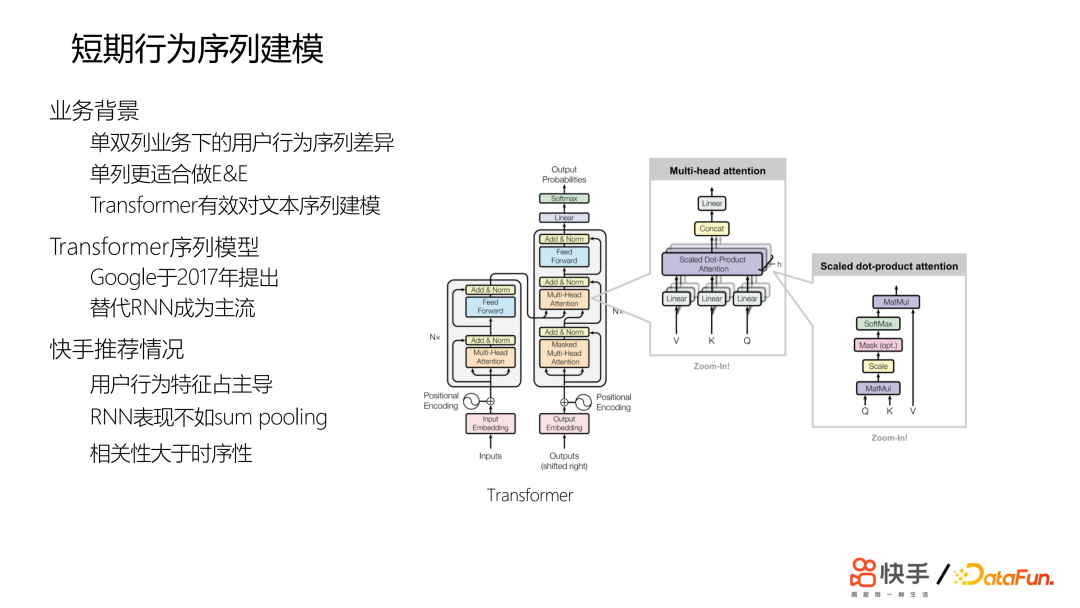
单双列场景下,用户的行为差异非常大,单列可能更适合做 E&E,业界开始使用 transformer 有效对文本序列建模。推荐场景用户的交互行为量非常大,用户行为特征比例也非常高,而且在当时做了非常多的行为序列建模的尝试,但是收益不显著。相对来说,对于序列建模可能相关性大于时序性,换言之要推荐的视频与用户历史的相关性会更重要一些。2. 算法改进
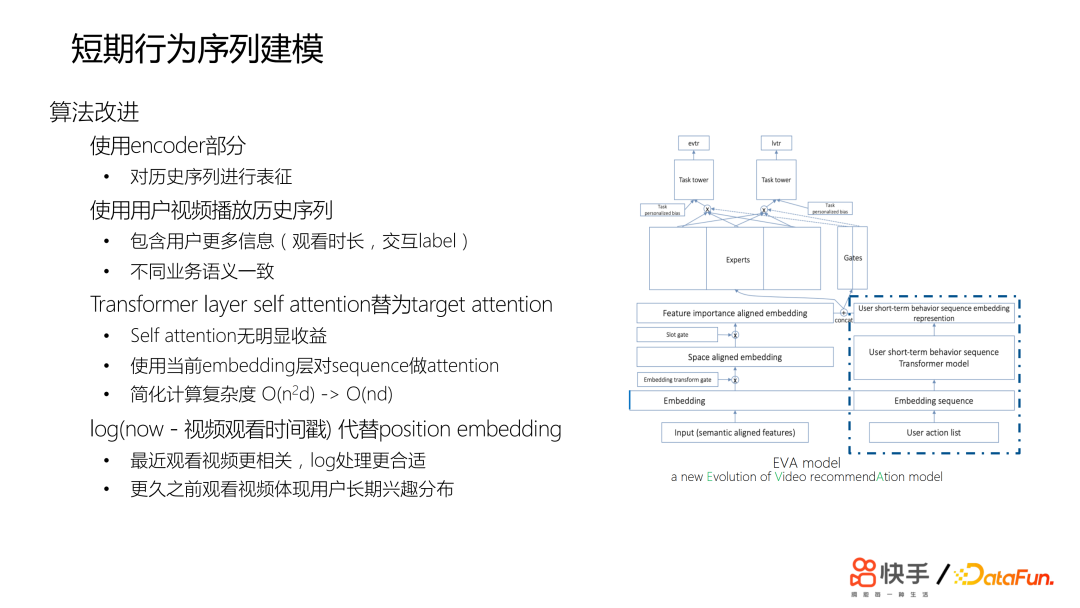
我们针对业务特点对算法进行了改进。只使用了 encoder 的部分,encoder 是对用户的历史序列的表征,处理用户的短期行为历史,主要是用户播放历史序列,主要包含用户交互 label。用户的视频观看历史在不同业务下的语义非常一致。使用 Target Attention 来替换 transformer self attention 部分,发现 self attention相对于 Target Attention 并没有显著的收益,但是计算量非常大。以此替换可以降低计算的复杂度。使用视频观看时间戳取代 position embedding。短期行为序列建模希望模型更关注近期的观看历史行为。该模型收益非常显著。05长期行为序列建模
1. 困难和挑战
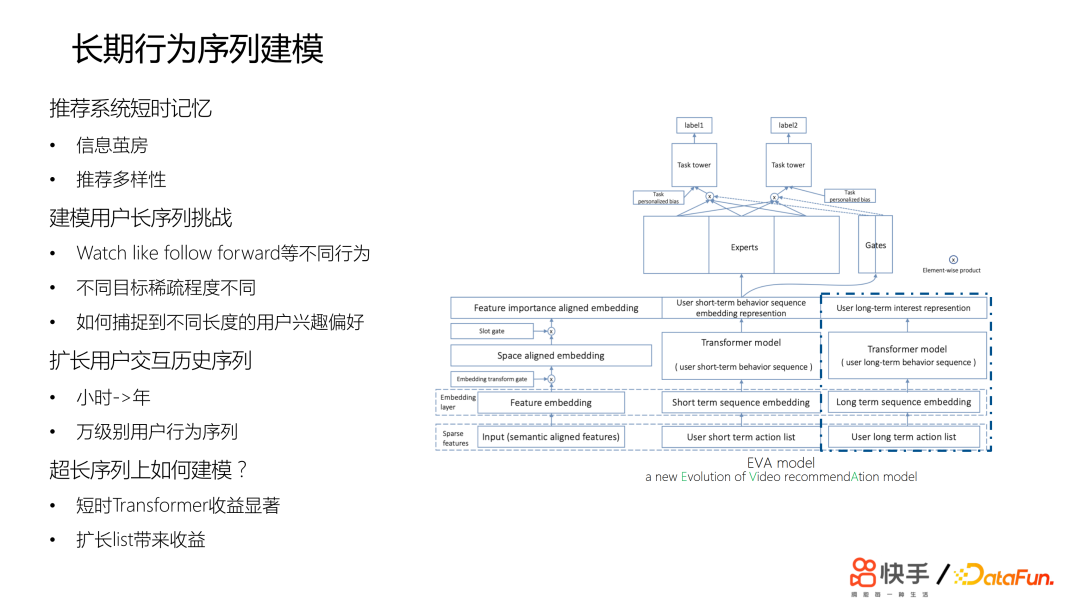
长期行为序列建模是非常重要的,如果没有长期行为序列建模,推荐系统可能只有一些短时的记忆,会带来信息茧房的问题,会影响推荐多样性。建模用户长序列挑战在于,不同目标的稀疏程度是不同的,像观看时长,每个视频都会有观看时长;但是像 Like follow,如果交互率非常低就会非常稀疏。如何才能捕捉到不同长度的用户的兴趣偏好呢?2. 现有方案 SIM 及问题
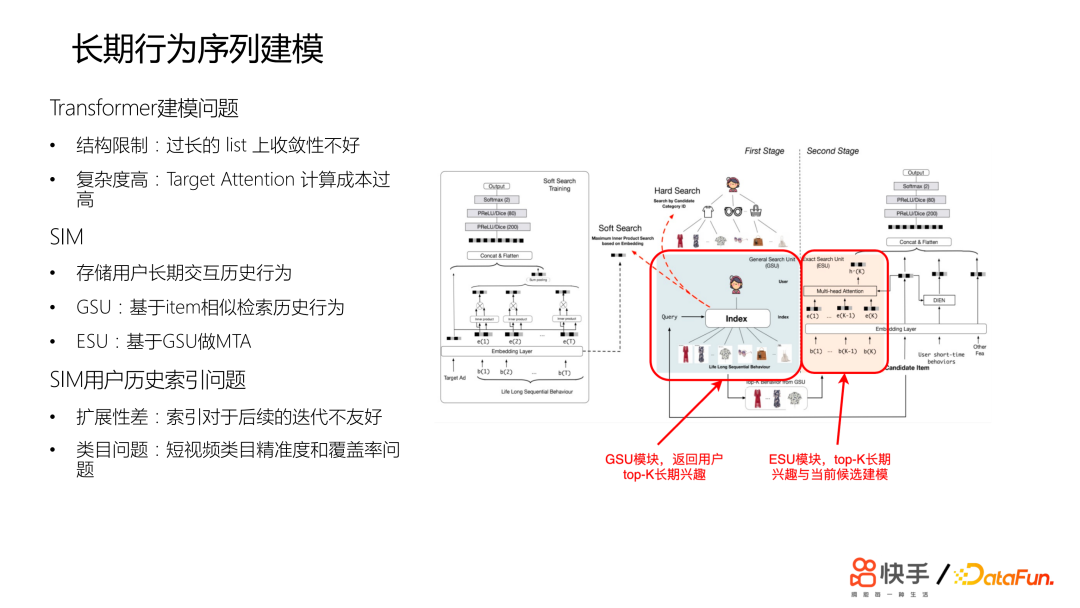
我们的目标是希望获得用户的交互历史,从只记录用户几小时的交互行为,能够扩大到年。这样可能达到万级的数量级。此外超长序列如何建模也是需要考虑的问题,认为扩长 list 应该会带来收益,但这也会带来困难。首先就是结构的限制,因为 transformer 在过长的 list 上收敛性并不好。另外复杂度会比较高,算力要求非常高。阿里巴巴已经有 SIM 的方案,存储了用户的长期的交互历史行为,然后做双阶段检索, 称为 GSU 模块和 ESU 模块。GSU 模块是返回用户 TOP K 的长期兴趣。兴趣是基于 Target item 检索的,具体实现使用二阶索引,第一阶索引是user,第二阶索引是类目,会根据要推荐的商品的类目来用户的交互历史去检索,把所有类目的交互历史都检索出来,取 TOP K,然后使用 Target Attention 做行为序列建模。该方案对于快手业务场景存在一些问题,首先扩展性非常差,对于后续算法迭代不太友好。其次是对于短视频类目精准度和覆盖率存在问题。3. 长期行为序列建模V1.0——基于 tag 检索
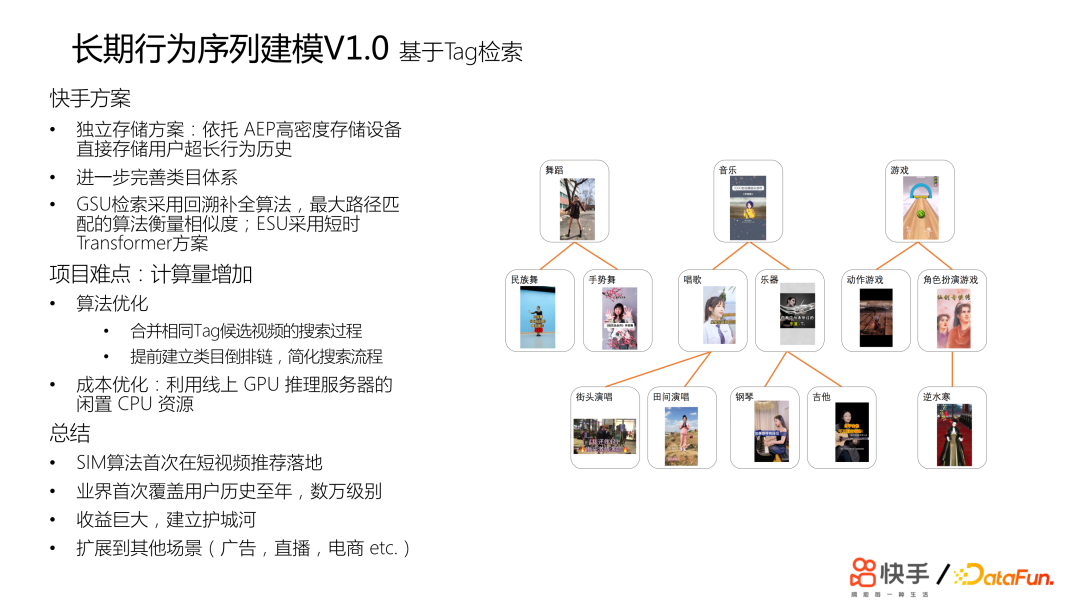
快手的方案我们称之为长期行为序列建模 V1.0,它也是基于 type 检索,但有一个独立的存储方案,依托于这种高密度存储设备的话,直接把用户的行为地址存储下来。此外,我们进一步完善类目体系。针对没有tag的很多视频,我们设计 JS 检索回溯的补全算法,使用最大路径匹配的方法来衡量相似度。4. 长期行为序列建模V2.0——基于Embedding距离检索
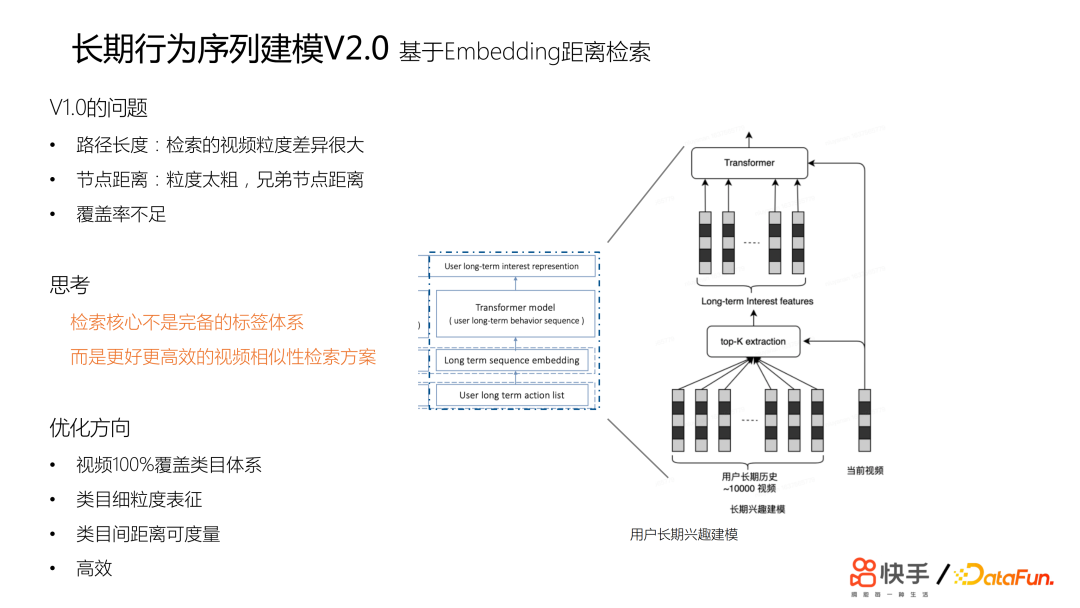
长期行为序列建模 V1.0 并不是最终的方案,它仍然存在一些问题,首先路径长度不一样,有的视频只能覆盖到更细的叶子节点,有的可能是覆盖到只能匹配到更高层的粗粒度的节点的话,检索的实施力度差异大会导致视频相似度问题。我们设定下一步的优化目标,希望短视频有百分之百覆盖的类目体系,对类目之间能够进行稀有的表征,类目之间距离可度量,而且要高效。其实我们优化的方向最开始还是针对 V1.0 的问题提出的一些优化方向,我们最终的方案先基于 embedding 做一次聚类,同时计算距离。这就是快手特色的长期行为序列建模的方案,是针对快手的业务特点,比如覆盖率等各种问题来设计的方案,收益非常大。06千亿特征万亿参数模型
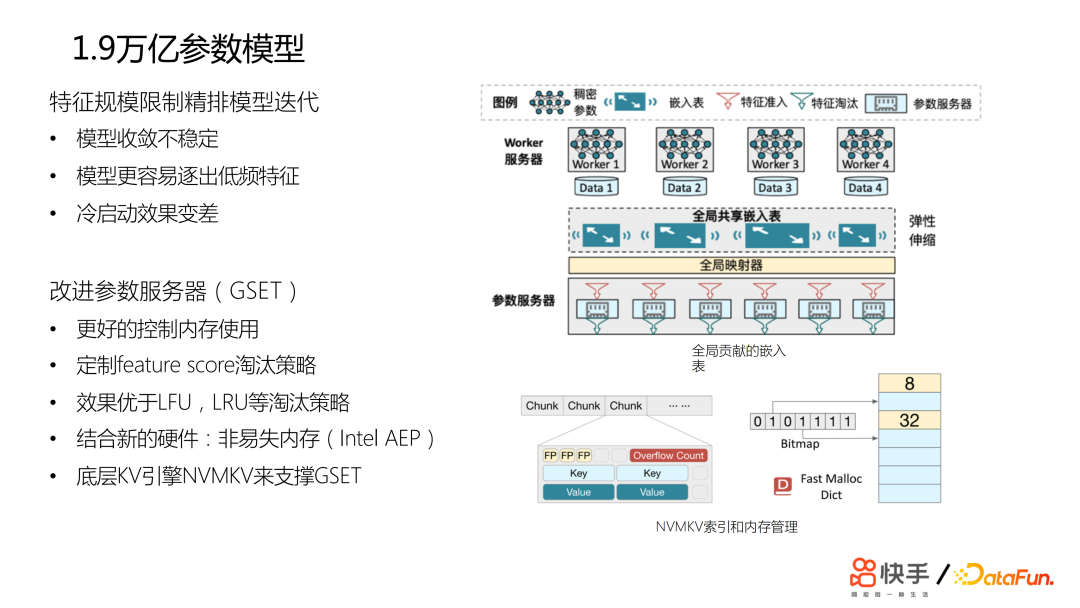
特征的规模会限制模型迭代,会影响模型收敛的稳定性,更容易逐出低频特征,冷启动效果变差。我们经过一些优化,特征量扩到了千亿规模,参数可以到万亿规模,这样也带来了不错的市场收益。07总结与展望我们未来的优化重点在以下几方面:
- 多业务下的模型融合
- 多任务学习
- 用户长短期兴趣建模&融合
- 用户留存建模
今天的分享就到这里,谢谢大家。

|分享嘉宾|

|《数据智能知识地图下载》|🔥业内首个《数据智能知识地图》已发布!涉及15个领域,133个体系框架,1000个细分知识点,欢迎大家下载!
上下滑动,查看推荐系统技术板块(完整版请关注公众号“大话数智”获取)


|商务合作|

|关于DataFun|
专注于大数据、人工智能技术应用的分享与交流。发起于2017年,在北京、上海、深圳、杭州等城市举办超过100+线下和100+线上沙龙、论坛及峰会,已邀请超过2000位专家和学者参与分享。其公众号 DataFunTalk 累计生产原创文章900+,百万+阅读,16万精准粉丝。
🧐 分享、点赞、在看,给个3连击呗!👇