

2550亿参数、免费可商用,前腾讯副总裁创业。编辑 | 香草智东西9月13日报道,今日,大模型创企元象XVERSE发布国内最大MoE开源模型XVERSE-MoE-A36B,其总参数2550亿,激活参数360亿,实现了达到千亿级别模型的性能“跨级”跃升。同时,这款MoE模型与其Dense模型XVERSE-65B-2相比,训练时间减少30%,推理性能提升100%,每token成本大幅下降。元象“高性能全家桶”系列全部开源,可无条件免费商用,为中小企业、研究者和开发者提供可按需选择的多款模型。
01.国内最大开源MoE模型无条件免费商用
不少行业前沿模型,包括谷歌Gemini-1.5、OpenAI的GPT-4、马斯克xAI的Grok等,都使用了MoE架构。MoE是业界前沿的混合专家模型架构,将多个细分领域的专家模型组合成一个超级模型,打破了传统扩展定律(Scaling Law)的局限,可在扩大模型规模时,不显著增加训练和推理的计算成本,并保持模型性能最大化。在权威评测中,元象MoE效果大幅超越多个同类模型,包括国内千亿MoE模型Skywork-MoE、传统MoE霸主Mixtral-8x22B以及3140亿参数的MoE开源模型Grok-1-A86B等。
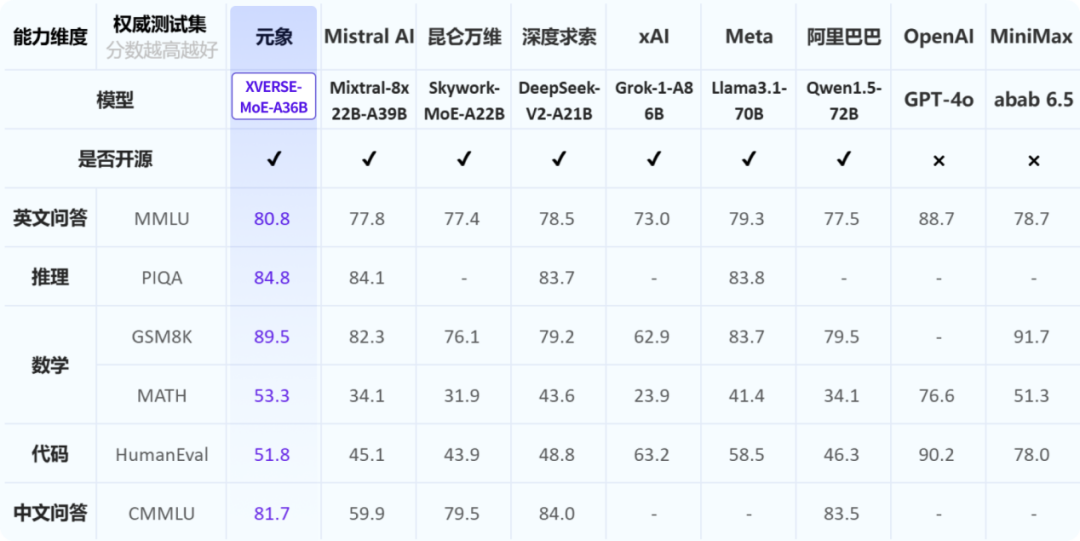
▲权威测试集评测结果
开发者现可在Hugging Face、GitHub等开源社区免费下载元象MoE大模型,并无条件免费商用。开源地址:https://huggingface.co/xverse/XVERSE-MoE-A36Bhttps://github.com/xverse-ai/XVERSE-MoE-A36B
02.数据动态切换、优化拓扑设计推理性能提升100%
通过设计与优化,元象MoE模型与其Dense模型XVERSE-65B-2相比,训练时间减少30%、推理性能提升100%,模型效果更佳,达到业界领先水平。具体来说,元象围绕效率和效果进行了MoE架构与4D拓扑设计、专家路由与预丢弃策略、数据动态切换等技术优化。MoE架构的关键特性是由多个专家组成。由于专家之间需要大量的信息交换,通信负担极重。为了解决这个问题,元象采用了4D拓扑架构,平衡了通信、显存和计算资源的分配。这种设计优化了计算节点之间的通信路径,提高了整体计算效率。MoE的另一个特点是“专家路由机制”,即需要对不同的输入进行分配,并丢弃一些超出专家计算容量的冗余数据。为此元象设计一套预丢弃策略,减少不必要的计算和传输。同时在计算流程中实现了高效的算子融合,进一步提升模型的训练性能。此外,MoE架构的专家之间需要大量通信,会影响整体计算效率。元象设计了“多维度的通信与计算重叠”机制,在进行参数通信的同时,最大比例并行地执行计算任务,从而减少通信等待时间。在专家模型权重方面,MoE中的专家总数为N,每个token会选择top K个专家参与后续的计算,由于容量限制,每个token实际选择到的专家数为M(M<=K<N)。被选择到的专家计算完之后,会通过加权平均的方式汇总得到每个token的计算结果,这里专家的权重如何设置是一个问题。元象通过对比实验的方式进行选择,根据对比实验的效果,最终选择“权重在top K范围内归一化”的设置进行正式实验。下图为对比实验的结果,其中实验1-4权重分别为top M、top K、top N范围内归一化以及1。
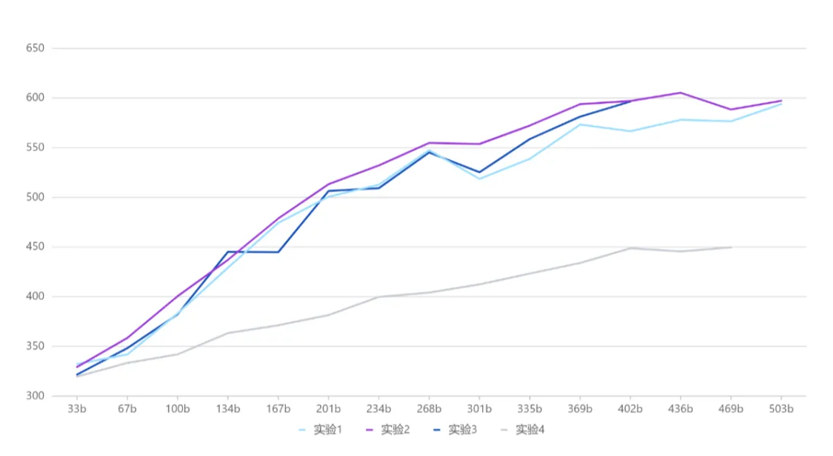
▲对比实验结果
元象以往开源的模型,往往在训练前就锁定了训练数据集,并在整个训练过程中保持不变。这种做法较为简单,但会受制于初始数据的质量和覆盖面。此次MoE模型的训练,元象借鉴了“课程学习”理念,在训练过程中进行动态数据切换,不同阶段多次引入新处理的高质量数据,并动态调整数据采样比例。这使得模型不再被初始语料集所限制,而是能够持续学习新引入的高质量数据,提升了语料覆盖面和泛化能力。同时,调整采样比例也有助于平衡不同数据源对模型性能的影响。
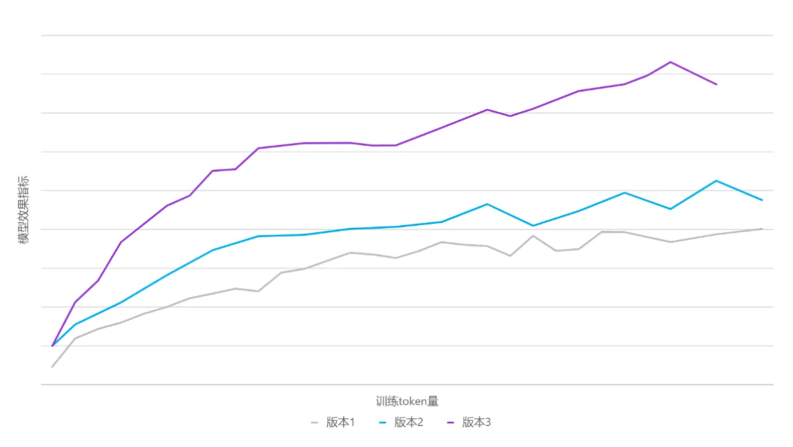
▲不同数据版本的效果曲线图
在训练过程中动态切换数据集也给模型带来了新的适应挑战。为了确保模型能快速且充分地学习新进数据,元象对学习率调度器进行了优化调整,在每次数据切换时会根据模型收敛状态,相应调整学习率。下图是整个训练过程中MMLU、HumanEval两个评测数据集的效果曲线图。这一学习率调度策略(LR Scheduler)有效提升了模型在数据切换后的学习速度和整体训练效果。
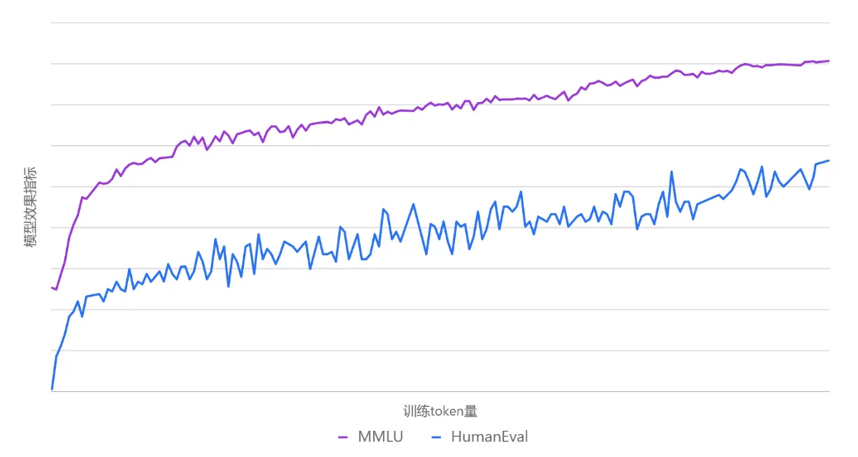
▲训练过程中MMLU、HumanEval的性能曲线持续提升
03.打造高性能开源全家桶自研AI互动网文App
元象于2021年初在深圳成立,是国内领先的AI与3D技术服务公司,专注于打造AI驱动的3D内容生产与消费一站式平台。元象创始人姚星是前腾讯副总裁和腾讯AI Lab创始人、国家科技部新一代人工智能战略咨询委员会成员。截至目前,元象累计融资金额超过2亿美元,投资机构包括腾讯、红杉中国、淡马锡等知名投资方。在3D领域,元象自研了“端云协同”3D互动技术,具备轻、快、美等优势。在AI领域,元象大模型最早开源了世界最长上下文大模型、国内首个65B大模型及前沿MoE模型等。基于对“通用人工智能(AGI)”的追求,元象持续打造“高性能开源全家桶”,不仅填补了国产开源空白,更将其推向了国际领先水平。2023年11月,元象率先开源了XVERSE-65B,是当时国内最大参数开源模型。
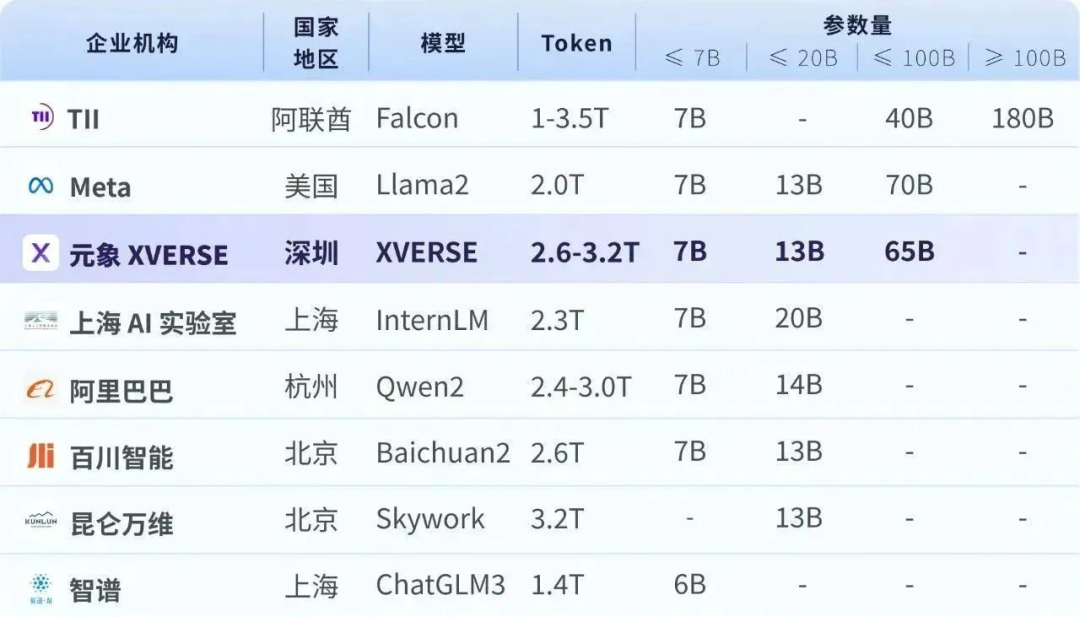
▲元象高性能开源全家桶
2024年1月,元象开源全球最长上下文窗口大模型,支持输入25万汉字,推动大模型应用进入“长文本时代”。
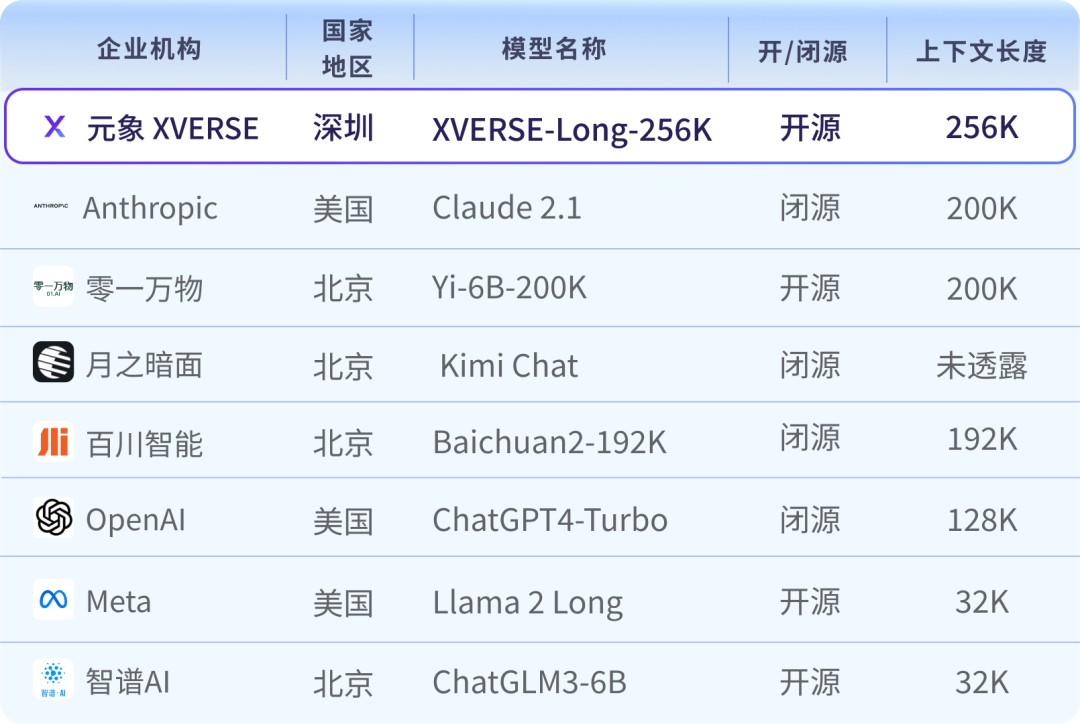
▲元象开源全球最长上下文窗口大模型
此次开源国内最大参数MoE模型,元象又为开源生态贡献了一个助推低成本AI应用的利器。在商业应用上,元象基于MoE模型自主研发了AI角色扮演与互动网文App Saylo,凭借逼真的AI角色扮演和有趣的开放剧情火遍港台,下载量在中国台湾和香港娱乐榜分别位列第一和第三。

▲元象自研AI角色扮演与互动网文App Saylo
在通用预训练基础上,元象使用海量剧本数据继续预训练(Continue Pre-training),其与传统SFT(监督微调)或RLHF(基于人类反馈的强化学习)不同,采用了大规模语料知识注入,让模型既能保持强大的通用语言理解能力,又大幅提升了“剧本“这一特定应用领域的表现。
04.结语:国产开源模型推动AI应用落地
元象在大模型领域的不断突破与创新,为国产开源大模型的发展注入了新的动力,也推动了应用落地的加速。在落地层面,元象从去年起陆续与QQ音乐、虎牙直播、全民K歌、腾讯云等软件深度合作,基于大模型为文化、娱乐、旅游、金融等领域打造了创新领先的用户体验。
(本文系网易新闻•网易号特色内容激励计划签约账号【智东西】原创内容,未经账号授权,禁止随意转载。)
