▲头图由AI生成
国内首个全面开源百亿级大语言模型、目前最大的中文开源数据集之一发布。
编辑
| ZeR0智东西10月30日报道,今日,昆仑万维正式发布国内首个全面开源百亿级大语言模型「天工」Skywork-13B系列,600GB、150B Tokens的高质量中文开源数据集,并全面开放商用。也就是说,开发者无需额外申请,即可将大模型进行商业用途,而且开源得足够彻底,没有对行业、公司规模、用户等方面的任何限制。2008年成立、从游戏起家的昆仑万维,近年已逐渐构建了AGI与AIGC、海外信息分发与元宇宙、投资三大业务板块,业务覆盖全球一百多个国家和地区,全球平均月活跃用户近4亿。昆仑万维「天工」Skywork-13B系列拥有130亿参数,包含Skywork-13B-Base、Skywork-13B-Math两个大模型,在CEVAL、GSM8K等多个权威评测与基准测试上都展现了同等规模模型的最佳效果,在中文科技、金融、政务等领域表现均高于其他开源模型。除模型开源外,Skywork-13B系列大模型还将开源600GB、150B Tokens的高质量中文语料数据集Skypile/Chinese-Web-Text-150B,这是目前最大的中文开源数据集之一。
Skywork-13B下载地址:
https://modelscope.cn/organization/skywork
https://github.com/SkyworkAI/Skywork
01.130亿参数、两大模型、150B中文数据集,全面开放商用!
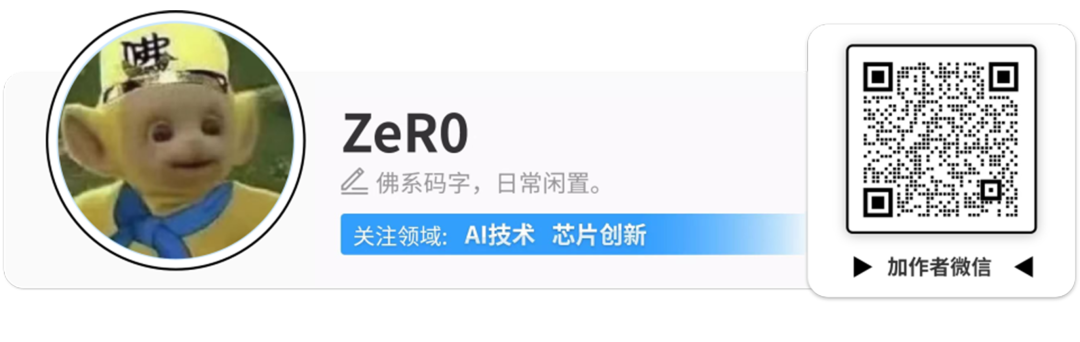
昆仑万维「天工」Skywork-13B系列包括两大模型及150B高质量中文数据集。其中,Skywork-13B-Base模型是基础模型,由3.2万亿个多语言高质量数据训练而成,在CEVAL、CMMLU、MMLU、GSM8K等评测与基准测试上都展现了同等规模模型的最佳效果。Skywork-13B-Math模型,顾名思义,经过专门的数学能力强化训练,在GSM8K等数据集上取得了同等规模模型的最佳效果。Skypile/Chinese-Web-Text-150B数据集,是根据昆仑万维经过精心过滤的数据处理流程从中文网页中筛选出的高质量数据。本次开源数据集大小约为600GB,包含约1500亿个token,是目前最大的开源中文数据集之一。
除此之外,Skywork-13B系列还公开了模型中使用的评估方法、数据配比研究和训练基础设施调优方案等。为了更加精细化利用数据,Skywork-13B系列采用两阶段训练方法,第一阶段使用通用语料进行模型通用能力学习,第二部分加入STEM(科学,技术,工程,数学)相关数据进一步增强模型的推理能力、数学能力、问题解决能力。昆仑万维希望这些开源内容能够进一步启发社区对于大型模型预训练的认知,并推动人工智能通用智能(AGI)的实现。
02.五大特点:评测得分超越Llama 2,无需申请即可商用
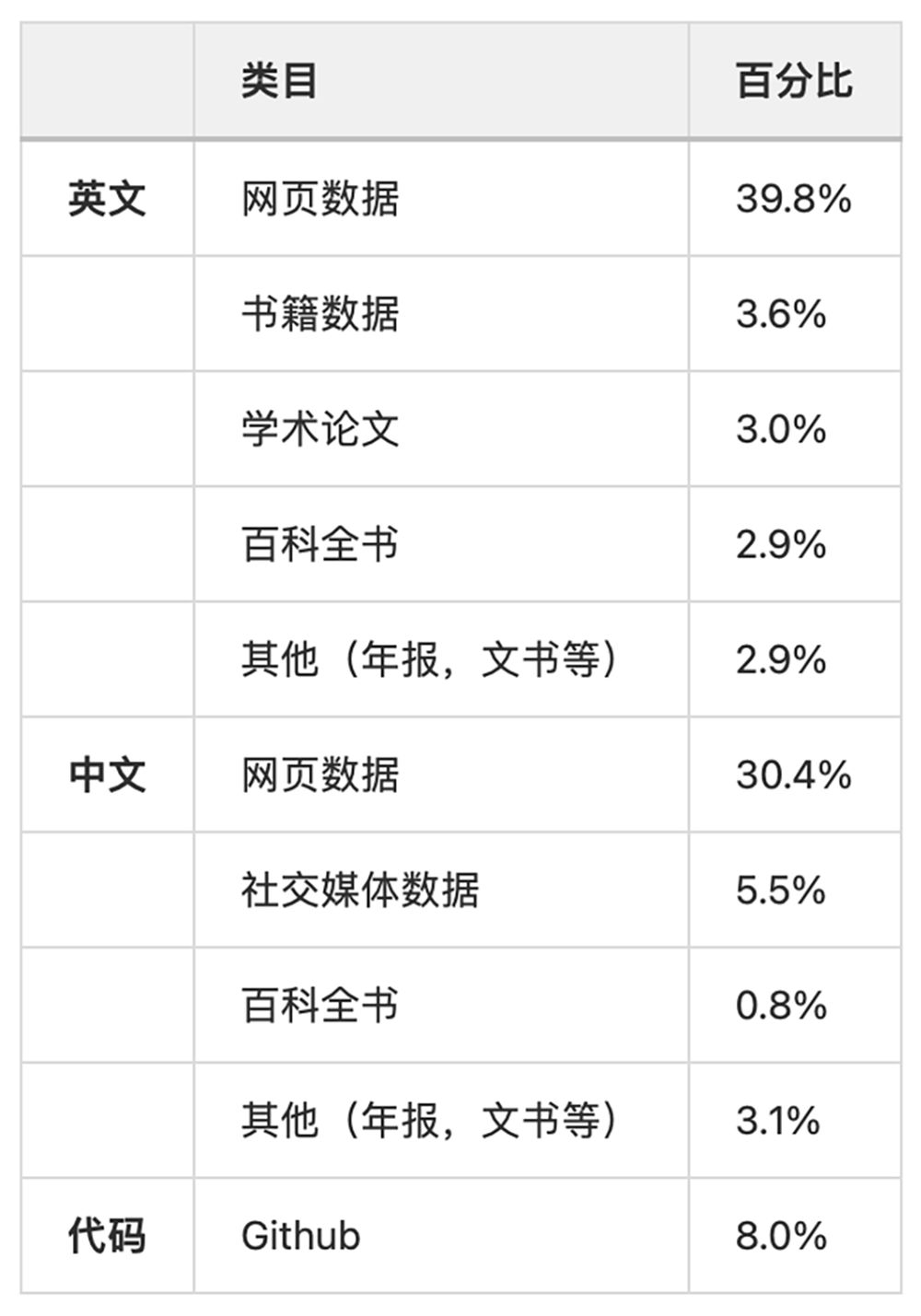
昆仑万维「天工」Skywork-13B系列大模型在CEVAL、GSM8K等多个权威评测与基准测试上都展现了同等规模模型的最佳效果,其中文能力尤为出色,在中文科技、金融、政务等领域表现均高于其他开源模型。昆仑万维将该系列大模型的特点总结为五个“最”:1)最强参数表现:根据截至10月25日的数据,Skywork-13B系列模型在CEVAL、CMMLU、MMLU、GSM8K等权威评估基准中全面超越Llama-2-13B等开源大模型,在同等规模大模型间取得最佳效果。
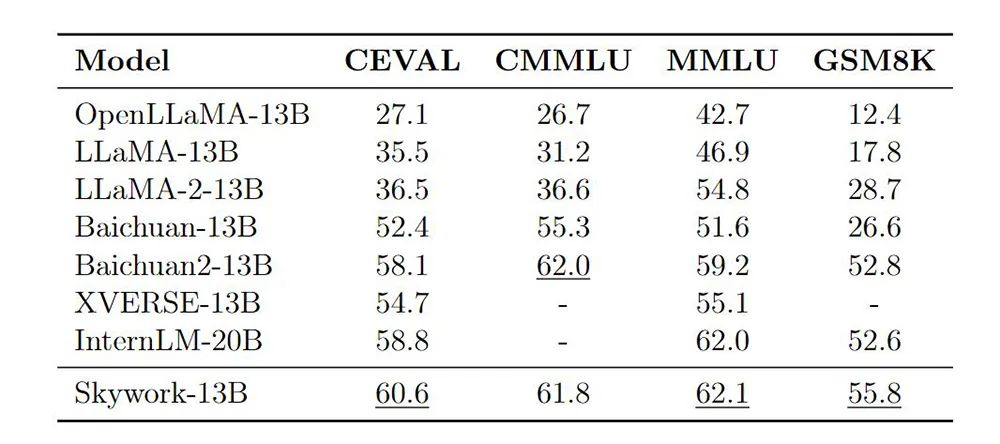
与Llama-2-13B相比,天工Skywork-13B模型采用相对更加瘦长的网络结构,层数为52层,同时将FFN Dim和Hidden Dim缩小到12288和4608,从而保证模型参数量和原始Llama-13B模型相当。据昆仑万维前期实验对比,相对瘦长的网络结构在大Batch Size训练下可以取得更好的泛化效果。
2)最多训练数据:拥有130亿参数、3.2万亿高质量多语言训练数据,模型的生成能力、创作能力和数学推理能力提升明显。3)最强中文语言建模能力:中文语言建模能力、中文文创能力出色,在科技、金融、政务、企业服务、文创、游戏等领域的中文文本创作评测中表现均高于业内其他开源模型。
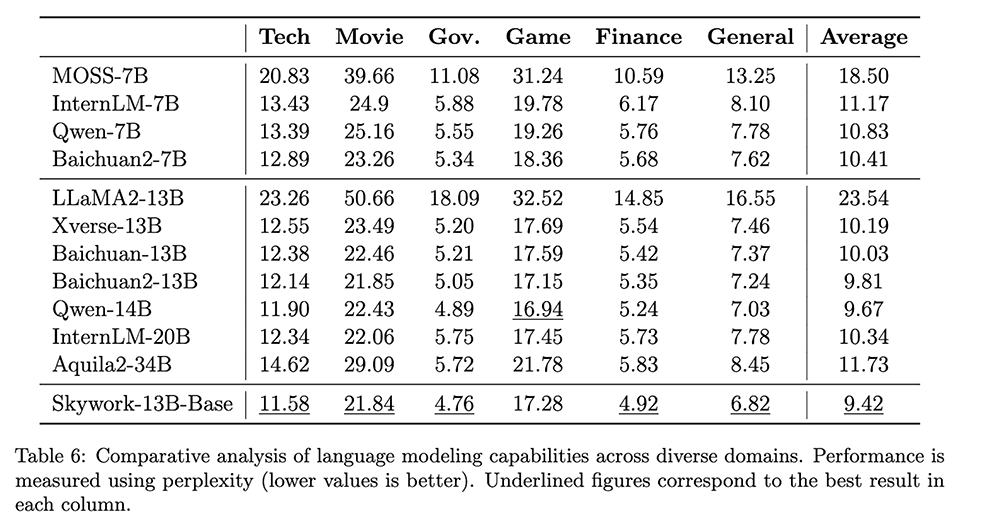
如图用领域数据困惑度来衡量语言模型跨领域的语言建模能力。评估一个基础大模型的重要方式是评估其在各领域上生成文章的概率,困惑度通过评估模型预测下一个词的平均可选数量来衡量一个语言模型的好坏。困惑度越低,意味着语言模型生成高质量文本内容的能力越强。4)最大中文开源数据集之一:将配套开源600GB、150B Tokens的高质量中文语料数据集Skypile/Chinese-Web-Text-150B。开发者可以最大程度地借鉴技术报告中大模型预训练的过程和经验,深度定制模型参数,有针对性的进行训练与优化。5)最有诚意的开源商用:全面开放商用许可,将授权流程做到极简,取消对行业、公司规模、用户等方面的限制,用户在下载模型并同意并遵守《Skywork模型社区许可协议》后,无需再次申请授权,即可将大模型进行商业用途。目前开源社区中的中文大模型多数并非是完全可商用,用户通常需要进行复杂的商用授权申请流程,有些情况会对公司规模、所在行业、用户数等维度有明确规定不给予商业授权。昆仑万维希望用户能够更便捷地探索Skywork-13B系列大模型技术能力,探索在不同场景下的商业化应用,以帮助更多对中文大模型感兴趣的用户和企业在行业中不断探索和进步。
03.形成六大AI业务矩阵,以All in AGI与AIGC为战略重心
昆仑万维成立于2008年,从游戏起家,2015年在深交所上市,2020年便已开始布局AIGC领域,正全面构建多元化的业务生态。至今,昆仑万维已积累近三年的相关工程研发经验,并建立了行业领先的预训练数据深度处理能力,在AI领域已形成AI大模型、AI搜索、AI游戏、AI音乐、AI动漫、AI社交六大AI业务矩阵。All in AGI与AIGC是昆仑万维的战略。据了解,昆仑万维董事长兼CEO方汉是很早参与到开源生态建设的开源老兵,也是中文Linux开源最早的推动者之一,因此开源精神和AIGC技术发展的结合将会贯穿于昆仑万维战略之中。今年以来,昆仑万维一路快马加鞭,释出从基础大模型到AIGC产品的一系列进展:4月17日,昆仑万维发布自研千亿级大语言模型「天工3.5」,并启动邀请测试。该模型具备文案创作、知识问答、代码编程、逻辑推演、梳理推算等多元AI生成能力。5月19日,北京市经济和信息化局公布第一批《北京市通用人工智能产业创新伙伴计划成员名单》,昆仑万维成为第一批模型伙伴和投资伙伴。8月23日,昆仑万维发布国内第一款AI搜索产品——天工AI搜索,并开启内测申请。天工AI搜索通过人性化、智能化的方式全面提升用户的搜索体验,并集成AI对话、AI写作等常用功能,帮助用户提高中文搜索体验和工作效率。9月1日,计算机视觉和机器学习领域的国际顶级专家颜水成教授正式加盟昆仑万维,与昆仑万维创始人周亚辉一起出任天工智能联席CEO,并兼任昆仑万维2050全球研究院院长,负责前沿技术的研究。9月5日,昆仑万维天工大模型在腾讯优图实验室联合厦门大学开展的多模态大语言模型测评MME中,综合得分排名第一。9月17日,昆仑万维通过信通院“可信AI”评估,并被评选为人工智能实验室副组长单位。9月25日,昆仑万维正式控股AI大算力芯片企业艾捷科芯,布局AI芯片。10月26日,天工大模型获得由北京算法交易服务中心颁发的“算法模型认证证书”,昆仑万维成为北京算法交易服务中心首批认证企业。今天,天工Skywork-13B系列大模型的开源,标志着昆仑万维持续投资AGI生态的决心。
04.结语:推动开源生态繁荣,加速AI技术落地
蓬勃发展的开源生态建设是构建AI和应用融合的重要一环。持续降低模型的研发门槛、使用成本、最大化的共享技术能力和经验,有助于加速AI应用普及,促使更多的企业和开发者们参与到AI引领的科技变革中。昆仑万维表示Skywork-13B系列大模型的开源将为大模型的场景应用和开源社区发展提供最佳的技术支持,加速开源生态繁荣,进而降低大模型商业门槛,推动AI技术落地千行百业。