
中国需要什么样的大模型?三路玩家答案只有一个。作者 | 三北编辑 | 漠影随着「百模大战」狂飙200多天,国内大模型产业正以超乎想象的速度发展。大模型数量不断膨胀,根据国研经济研究院10月23日发布的最新报告,我国大模型截至2023年8月已达156个,超10亿级参数的大模型超80个,比肩美国。「百模大战」进入深水区,形成了互联网大厂、科技行业龙头、AI创企三路玩家割据,在能力上对标GPT-4,在产业化实战中混战的格局。当下AI正成为国家「新基建」的重要部分。大量算力设施在加速建设和启用,海量的数据不眠不休地在万卡集群流转。国内锻造的大模型与GPT-4还有多远的距离?同时,在全球AI竞赛激烈、供应链紧张的背景下,中国需要什么样的大模型?这些都成为产业迫切探讨的问题。每一家大模型企业都在寻找大模型的中国方案,作为AI国家队的科大讯飞也不例外。随着全面对标ChatGPT的讯飞星火认知大模型V3.0面世,面向医疗、教育、工业等各行各业的行业大模型进入人们的生产和生活,讯飞也与17+万新增大模型开发者、10万+企业客户一起,交出了一张「新答卷」。
01.「百模大战』进入深水区
三路玩家混战
人工智能从1956年被正式提出以来,经历了数十年的发展历程。大模型的诞生,一举实现统计学习流派成果的集大成,成为当下AI研究和开发的最有力武器,也成为各大科技公司的必争市场。根据行研机构IDC今年8月发布的报告,2022年全球人工智能IT总投资规模为1288亿美元(约合9422亿元人民币),在大模型的推动下2027年预计增至4236亿美元(约合3.1万亿元人民币)。事实上,围绕大模型的全球AI竞赛已经愈演愈烈。不仅微软及OpenAI、谷歌、Meta等企业之间打得正激烈,多国政界高层也已发声,推动新政策、联盟和国家项目的建设。而我国,同样迫切需要大模型。浩浩荡荡的「百模大战」在我国已打响半年,在中央和地方的多重政策指引下,各个领域的「头雁」已经加入探索中国大模型方案的浪潮之中。在「百模大战」狂飙的200多天里,我们看到有三路玩家冲出重围,分别是:以百度、阿里等为代表的互联网大厂,以华为、讯飞等为代表的科技行业龙头,还有智谱AI、百川智能等一众AI创企。谁能够打造出中国最需要的大模型?我们看到,三路大军探索了自然语言、视觉和多模态不同方向,也正进入互联网、医疗、金融、教育、工业等各个行业领域。而随着8月15日工信部等七部门联合发布的《生成式人工智能服务管理暂行办法》施行,一些头部选手的大模型纷纷面向公众开放,包括百度、智谱AI、科大讯飞、商汤科技、阿里云、百川智能、MiniMax、抖音、中科院、上海AI实验室等首批开放企业都在争抢「第一梯队」的名额。一个初步的大模型「第一梯队」玩家阵营已经出现。刘聪告诉智东西,当下大模型产业正处于大浪淘沙的关键阶段。根据新华社联合北大最新发布的《人工智能大模型体验报告2.0》报告,基于基础能力指数、智商指数、情商指数、工具提效指数四大维度测评,讯飞、百度、商汤、智谱的大模型综合能力已居于前列。
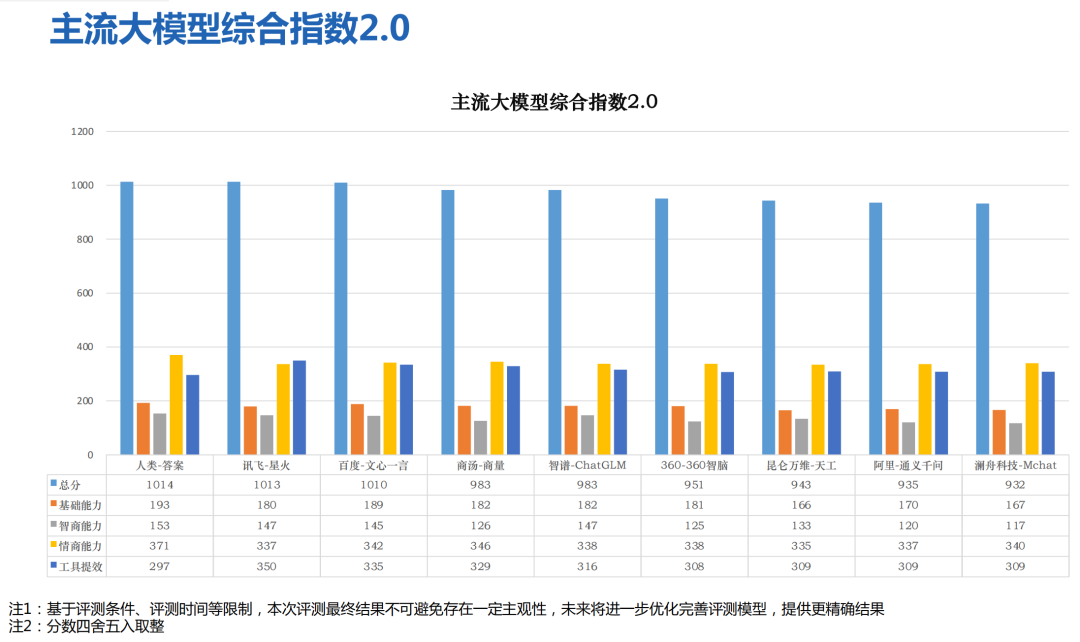
▲《人工智能大模型体验报告2.0》主流大模型综合指数2.0
更值得一提的是,这些大模型之间已经出现了打法和效果上的差异。根据《人工智能大模型体验报告2.0》报告,百度文心一言地基深厚、基础能力仍处领军水准;商汤商量在情商方面表现优秀;智谱在智商能力方面表现较好;科大讯飞的星火在工作提效方面优势明显。在10月23日国研经济研究院最新发布的测评中,讯飞星火大模型则大幅超越ChatGPT,并在部分行业优于GPT-4,该榜单主要针对的是法律服务、工业设计、医疗、教育、零售、汽车工程、计算机7个行业的测评。分野初现,那么中国究竟需要什么样的大模型?答案正变得日益明晰。
02.国产大模型围攻GPT
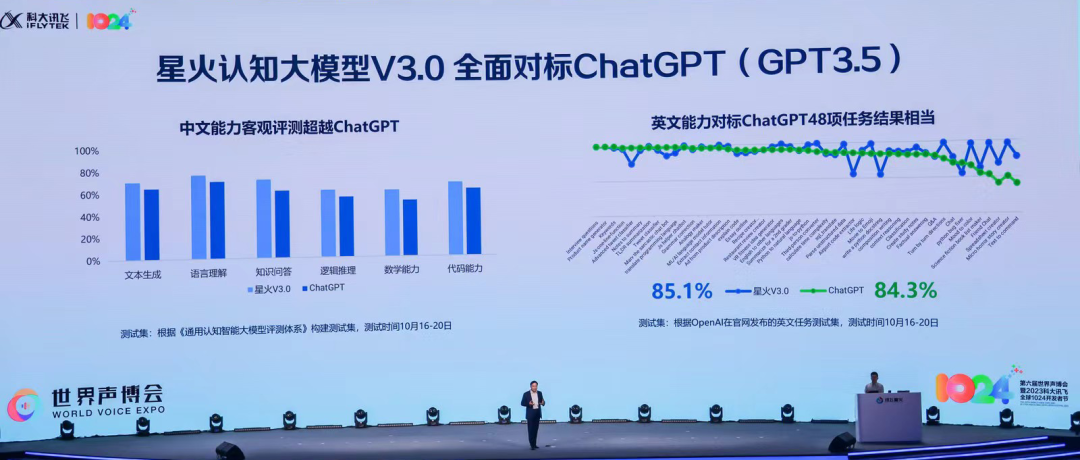
中国需要的大模型,首先是能力强大的模型。各家大模型的功能定义有所区别,但无一例外都将技术对标OpenAI的GPT。在AI领域深耕多年的科大讯飞董事长刘庆峰认为,国产大模型必须正视和GPT-4的差距。国产大模型在复杂知识推理、小样本快速学习、超长文本处理、跨模态统一理解上距GPT-4还有差距。唯有实事求是的科学精神,才能真正实现超越。科大讯飞星火认知大模型V3.0从文本生成、语言理解、知识问答、逻辑推理、数学能力、代码能力、多模态能力七大能力方面进行了攻关,全面对标ChatGPT,据称目前中文能力客观评测已超越ChatGPT,英文能力对标ChatGPT的48项任务结果相当。背后,大模型的迭代要求研发团队从数学自动提炼规律、小样本学习、代码项目级理解能力、多模态指令跟随与细节表达等各种细分能力着手,逐个攻关。综合应用迭代之后的大模型多项能力,用户能够做很多原本无法完成的创作。比如人机协同创作绘本故事,输入简单的提示词,就能连续生成图文并茂的故事。文字故事的上下连续性,绘图中人物形象的连续性,都来自星火大模型的认知能力。而当大模型的能力起来之后,如何让大模型体验更好?讯飞主张根据海量用户反馈做大模型升级。比如自讯飞星火9月5日全民开放至今已有1200万用户,他们对认知大模型提出了更高期待:不仅能回答问题,还要能提出问题;不仅要有知识,还要有个性。这让讯飞意识到了“人格化”对AI大模型产品的重要性。为此,讯飞星火大模型V3.0新增了AI人设功能,它可以根据性格模拟、情绪理解、表达风格来形成一个初始人设,再结合特定知识学习、对话记忆学习,形成一个更个性化的AI人设。比如基于AI人设应用助手“友伴”,创建一个自己的人设助手,上传个人背景知识,大模型便能用本人的风格进行对话。当创建一个“孔夫子”助手来写发言稿时,孔夫子的声音和语言风格便展现出来。可以看到,国产大模型正逐渐找到自己的能力圈。而随着国内大模型找到发展之路,国外的OpenAI也正凭借GPT技术起飞。据外媒The Information报道,OpenAI的首席执行官萨姆•阿尔特曼(Sam Altman)10月对其员工透露,OpenAI今年营收达到了13亿美元,同比增长超4500%,这将支持OpenAI进一步计划融资超千亿美元。OpenAI让中国企业看到了大模型技术的可观商业前景,也感受到了产业化落地的压力。中国的大模型能否像OpenAI在商业中取得初步成功?讯飞已用行动给出了笃定的答案:对标GPT-4的更大参数规模的星火大模型正式启动训练,2024年将实现对标GPT-4。与此同时,星火大模型的产业化也已经同步展开。
03.从工业生产到社会刚需
大模型跑出中国化道路
中国需要的大模型,是用技术创新去解放生产力的大模型。AI正上升为国家政策导向,大模型日益以「新基建」的模式服务社会。高层强调人工智能是新一轮科技革命和产业变革的重要驱动力量,各地政府此前已经陆续推出了大模型相关行动方案,通过算力券、资金补贴、产业场景扶助等方式支持大模型发展;一些城市如上海已率先将发展大模型写进新基建行动方案,以推动大模型融入产业升级和社会生产力发展。讯飞明确提出要将星火认知大模型打造成解放生产力的工具,且从推出第一天起就聚焦应用落地。随着讯飞星火App推出,其用户使用的高峰期集中在"10 点、15 点"两个办公时段,印证了讯飞星火大模型更贴合“解放生产力、释放想象力”的需求。随着技术的进步持续推动应用落地,星火认知大模型在解决教育、医疗等社会刚需等问题上日益深入。1、面向工业、科研领域,大模型助力降本增效随着产业数字化和数字产业化发展,中国软件从业人员快速增长,已有约800万人,2022年软件业务收入10.8万亿元。为此,大模型在工业领域首先要赋能代码。过去半年来,我们看到Copilot X等多种编程辅助工具诞生,而基于讯飞星火V3.0的智能编程助手iFlyCode2.0则再攀高峰。据称,其在编程的设计阶段提效50%、编码阶段提效37%、测试阶段提效44%。iFlyCode推出以来,已在京东云、软通动力等107家机构实现深度对接应用。科学技术是第一生产力,大模型也在为科研人员“加Buff”。当下,科学技术在大国角逐中的地位越来越重要。而在科研领域,科研人员往往会花大量的时间在资料的检索和整理上。如果能将他们从中解放出来,那么他们就能够去研究解决更加“卡脖子”的问题。科技文献是检验大模型高阶认知能力的“试金石”,也成为大模型企业重要的落地方向。以讯飞星火和与中科院文献情报中心联合打造的科技文献大模型为例,其可以实现成果调研、论文研读、学术写作三大功能。比如基于科技文献大模型,可以将十几份量子计算论文一键生成综述报告,让科研人员快速了解最新学术新知。测试显示,基于科技文献大模型,学者成果调研的效率可以提高超10倍,模型的论文研读有效率和学术写作采纳率均超90%。2、面向教育、医疗领域,大模型满足更广大社会刚需一个国家未来的科技发展、科学精神,应该从娃娃抓起。通用人工智能时代,真正的“因材施教”、“个性化学习”有望进一步实现。比如,讯飞AI学习机主推的「启发互动式英语AI答疑辅学」功能,就可以实现个性化解决、启发引导式提问、互动探究式学习。根据2023年9月安徽地区七八年级试点用户的统计数据显示,基于AI答疑辅学功能,小学英语错题解决率提升了13%,初中英语错题解决率提升了61%。如何缓解医疗资源紧张的问题?大模型现在也能起到作用。在医疗领域,讯飞的星火医疗大模型和基于星火医疗大模型的“讯飞晓医”APP开辟了问诊新路径。它支持人们在看病之前、用药有疑问、解析体检报告的时候进行建议询问。据悉,通过上线实际使用数据抽查12万例并通过STI第三方测试,讯飞星火医疗大模型在医疗海量知识问答、医疗复杂语言理解等方面全面超越GPT-4。大模型的落地领域还有很多,等待更多产业玩家一起探索。科大讯飞看准了包含金融、汽车、运营商、工业、住建、物业、法律等行业,联合行业龙头共同推出了12个行业大模型,加速产业升级。

▲讯飞与行业龙头联合在12个领域落地大模型
值得一提的是,认知大模型在行业深度应用的关键,无疑是安全可控、场景驱动、专属可控。其中安全可控的前提就是算力可控。我们看到,讯飞选择和华为在AI算力底座上打造基于昇腾生态的“飞星一号”大模型算力平台,正是为大模型在行业的深度应用提供了保障。最后,探索大模型落地应用的中国方案,离不开整个生态的支持。目前只有少数几家大模型头部玩家公布了最新生态建设情况。根据讯飞官方数据,自5月6日星火发布以来,讯飞开放平台新增143万开发者团队,同比增幅331%,汇聚553万AI生态开发者团队。其中新增大模型开发者17.8万,讯飞正与10万+企业客户用星火创新应用新体验。今年5月6日,讯飞发布星火认知大模型1.0版本,当时刘庆峰提出要「追赶并努力超越OpenAI」的目标,并放出在10月24日开发者节发布赶超ChatGPT的星火大模型的狠话,时隔近半年,讯飞果然兑现了承诺,交出大模型中国方案的「新答卷」。讯飞为什么能够一一兑现这些承诺?刘庆峰在此前的一次讲话中总结了讯飞做大模型的三点心得:1、首先是讯飞所有的算法都自主可控,这次星火大模型的每一行代码、每一个算法模块都是讯飞自己做的。2、讯飞有成建制的团队,讯飞还有像华为这样的深度合作伙伴,正因为有这些,讯飞才能够有底气说我下一阶段做到多少。3、因为除了技术、人才和伙伴之外,最重要的就是一定要完成任务,绝不服输,要做就勇争第一的精神,这就是中国通用人工智能未来的希望。
04.结语:理性看待与GPT的差距
着眼社会刚需发展大模型
当下,大模型产业面临激烈的算法竞争、严峻的算力限制、尚待发展成熟数据市场,都促使我们从根源处思考,中国究竟需要什么样的大模型?从中国经济的基本面来看,当前要提升实体经济投资回报率和提高劳动生产率,就需要在供给侧结构性改革等供给层面下功夫。正如望正资本全球宏观对冲基金董事长刘陈杰在中国宏观经济论坛所说,AI将成为一轮供给侧结构性改革2.0版本,特别是在发挥全要素生产力方面,AI将发挥特别重要的不可替代的作用。要服务社会生产力,大模型能力的及格关仍是第一步。诚然,国内「百模大战」中已经涌现出一批具有赶超GPT势头的玩家,但我们仍需要理性看待跟GPT的差距。以讯飞、百度、智谱AI等为代表的一梯队玩家从技术、产业和生态层面给出了有策略地进行超车方案,也做出了大模型与社会刚需相结合的价值选择。讯飞给出的大模型中国方案兼顾了这些问题的方方面面。首先,中国需要在正视GPT-4的基础上,打造自主创新、安全可控、不断超越的大模型;其次,大模型要聚焦社会刚需的解决,而不是仅用于社交文娱等轻松领域;而从更宏观层面说,中国真正需要的是解决生产力的大模型,促进中国产业的新升级。值得一提的是,大模型在真正转化为生产力的过程中还会面临一系列新挑战。正如复旦大学人工智能创新与产业研究院院长漆远的观点,如何避免大模型出现的“幻觉效应”?对于复杂的应用场景如何实现信息的动态集成,包括代理如何调用外部数据库,大模型本身如何快速、动态地集成和更新?海量数据的获取和算力方面问题如何解决?这些都是大模型在研发和落地过程中难以绕过的挑战,也将成为中国大模型们需要直面的问题。(本文系网易新闻•网易号特色内容激励计划签约账号【智东西】原创内容,未经账号授权,禁止随意转载。)
