Stable Video 3D震撼登场:单图生成无死角3D视频、模型权重开放
机器之心报道
Stability AI 的大模型家族来了一位新成员。
昨日,Stability AI 继推出文生图 Stable Diffusion、文生视频 Stable Video Diffusion 之后,又为社区带来了 3D 视频生成大模型「Stable Video 3D」(简称 SV3D)。
该模型基于 Stable Video Diffusion 打造,能够显著提升 3D 生成的质量和多视角一致性,效果要优于之前 Stability AI 推出的 Stable Zero123 以及丰田研究院和哥伦比亚大学联合开源的 Zero123-XL。
目前,Stable Video 3D 既支持商用,需要加入 Stability AI 会员(Membership);也支持非商用,用户在 Hugging Face 上下载模型权重即可。

Stable Video 3D 的生成效果如下视频所示。
Stability AI 提供了两个模型变体,分别是 SV3D_u 和 SV3D_p。其中 SV3D_u 基于单个图像输入生成轨道视频,不需要相机调整;SV3D_p 通过适配单个图像和轨道视角扩展了生成能力,允许沿着指定的相机路径创建 3D 视频。
目前,Stable Video 3D 的研究论文已经放出,核心作者有三位。

技术概览
Stable Video 3D 在 3D 生成领域实现重大进步,尤其是在新颖视图生成(novel view synthesis,NVS)方面。
以往的方法通常倾向于解决有限视角和输入不一致的问题,而 Stable Video 3D 能够从任何给定角度提供连贯视图,并能够很好地泛化。因此,该模型不仅增加了姿势可控性,还能确保多个视图中对象外观的一致性,进一步改进了影响真实和准确 3D 生成的关键问题。
如下图所示,与 Stable Zero123、Zero-XL 相比,Stable Video 3D 能够生成细节更强、更忠实于输入图像和多视角更一致的新颖多视图。

此外,Stable Video 3D 利用其多视角一致性来优化 3D 神经辐射场(Neural Radiance Fields,NeRF),以提高直接从新视图生成 3D 网格的质量。
为此,Stability AI 设计了掩码分数蒸馏采样损失,进一步增强了预测视图中未见过区域的 3D 质量。同时为了减轻烘焙照明问题,Stable Video 3D 采用了与 3D 形状和纹理共同优化的解耦照明模型。
下图为使用 Stable Video 3D 模型及其输出时,通过 3D 优化改进后的 3D 网格生成示例。
Stable Video 3D 模型的架构如下图 2 所示,它基于 Stable Video Diffusion 架构构建而成,包含一个具有多个层的 UNet,其中每一层又包含一个带有 Conv3D 层的残差块序列,以及两个带有注意力层(空间和时间)的 transformer 块。
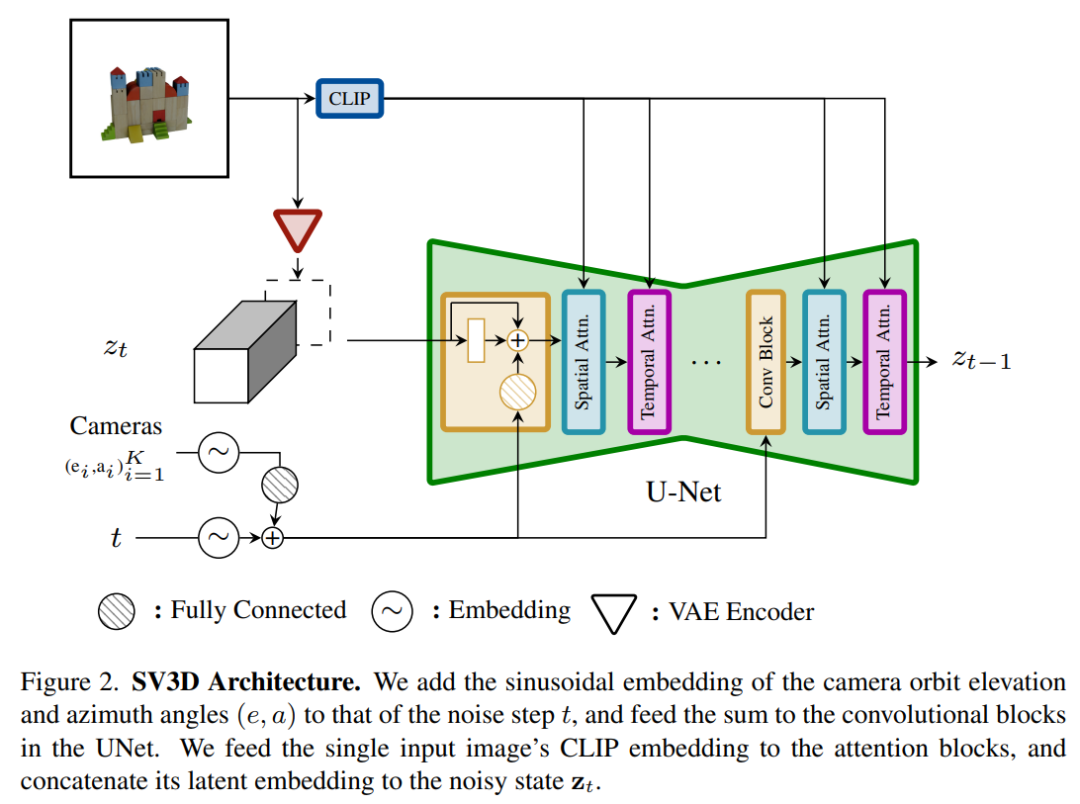
具体流程如下所示:
(i) 删除「fps id」和「motion bucket id」的矢量条件, 原因是它们与 Stable Video 3D 无关;(ii) 条件图像通过 Stable Video Diffusion 的 VAE 编码器嵌入到潜在空间,然后在通向 UNet 的噪声时间步 t 处连接到噪声潜在状态输入 zt;(iii) 条件图像的 CLIPembedding 矩阵被提供给每个 transformer 块的交叉注意力层来充当键和值,而查询成为相应层的特征;(iv) 相机轨迹沿着扩散噪声时间步被馈入到残差块中。相机姿势角度 ei 和 ai 以及噪声时间步 t 首先被嵌入到正弦位置嵌入中,然后将相机姿势嵌入连接在一起进行线性变换并添加到噪声时间步嵌入中,最后被馈入到每个残差块并被添加到该块的输入特征中。
此外,Stability AI 设计了静态轨道和动态轨道来研究相机姿势调整的影响,具体如下图 3 所示。
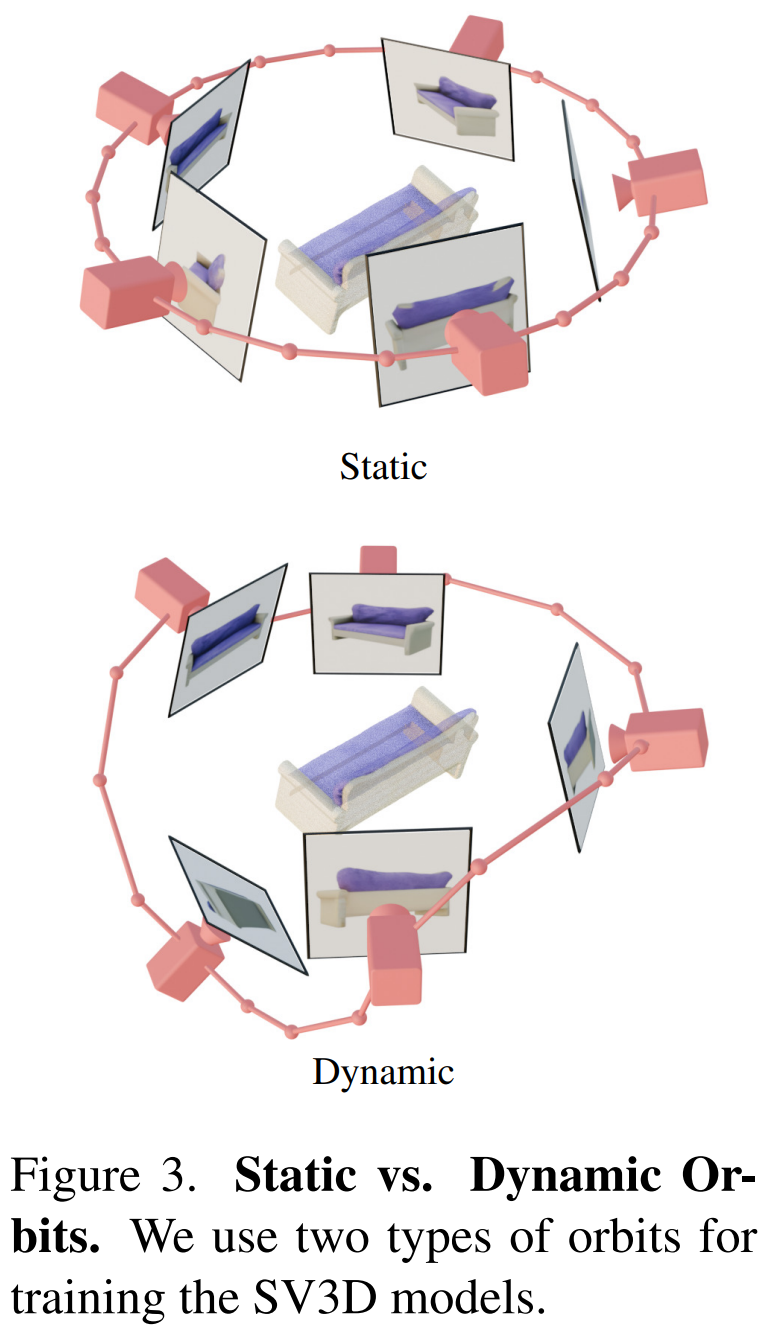
在静态轨道上,相机采用与条件图像相同的仰角,以等距方位角围绕对象旋转。这样做的缺点是基于调整的仰角,可能无法获得关于对象顶部或底部的任何信息。而在动态轨道上,方位角可以不等距,每个视图的仰角也可以不同。
为了构建动态轨道,Stability AI 对静态轨道采样,向方位角添加小的随机噪声,并向其仰角添加不同频率的正弦曲线的随机加权组合。这样做提供了时间平滑性,并确保相机轨迹沿着与条件图像相同的方位角和仰角循环结束。
实验结果
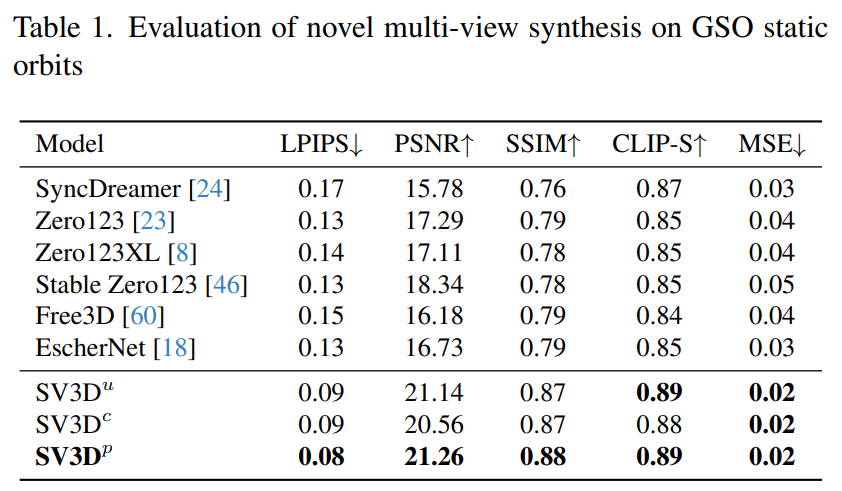
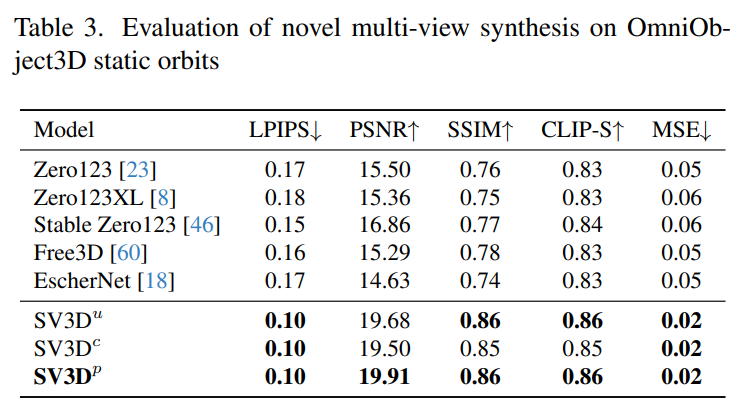
Stability AI 在未见过的 GSO 和 OmniObject3D 数据集上,评估了静态和动态轨道上的 Stable Video 3D 合成多视图效果。结果如下表 1 至表 4 所示,Stable Video 3D 在新颖多视图合成方面实现了 SOTA 效果。
表 1 和表 3 显示了 Stable Video 3D 与其他模型在静态轨道的结果,表明了即使是无姿势调整的模型 SV3D_u,也比所有先前的方法表现得更好。
消融分析结果表明,SV3D_c 和 SV3D_p 在静态轨道的生成方面优于 SV3D_u,尽管后者专门在静态轨道上进行了训练。
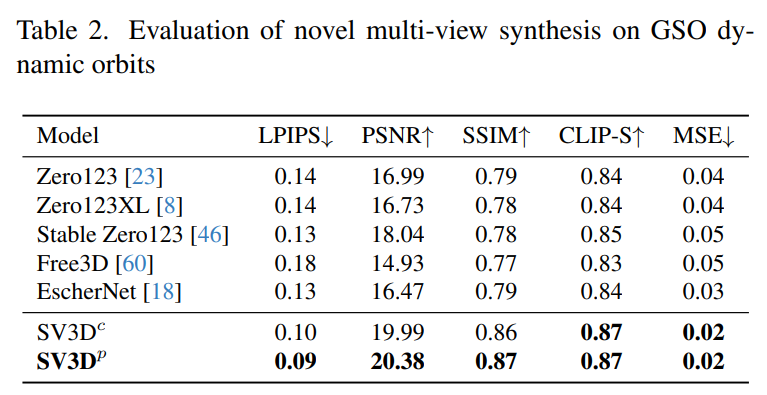
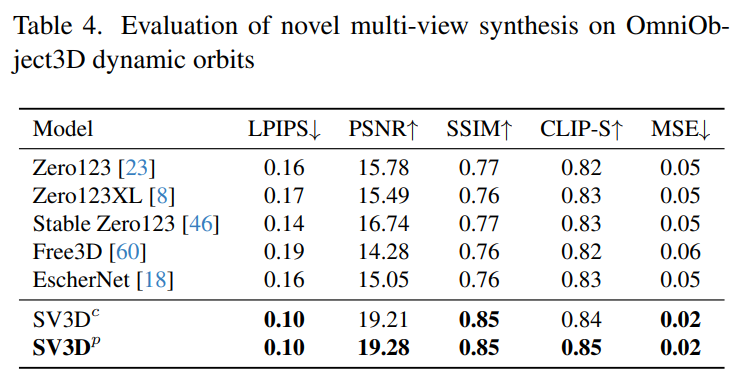
下表 2 和表 4 展示了动态轨道的生成结果,包括姿势调整模型 SV3D_c 和 SV3D_p,后者在所有指标上实现了 SOTA。
下图 6 中的视觉比较结果进一步表明,与以往工作相比,Stable Video 3D 生成的图像细节更强、更忠实于条件图像、多视角更加一致。

更多技术细节和实验结果请参阅原论文。

编辑:杜伟
3D 生成领域迎来新的「SOTA 级选手」,支持商用和非商用。
Stability AI 的大模型家族来了一位新成员。
昨日,Stability AI 继推出文生图 Stable Diffusion、文生视频 Stable Video Diffusion 之后,又为社区带来了 3D 视频生成大模型「Stable Video 3D」(简称 SV3D)。
该模型基于 Stable Video Diffusion 打造,能够显著提升 3D 生成的质量和多视角一致性,效果要优于之前 Stability AI 推出的 Stable Zero123 以及丰田研究院和哥伦比亚大学联合开源的 Zero123-XL。
目前,Stable Video 3D 既支持商用,需要加入 Stability AI 会员(Membership);也支持非商用,用户在 Hugging Face 上下载模型权重即可。
Stable Video 3D 的生成效果如下视频所示。
Stability AI 提供了两个模型变体,分别是 SV3D_u 和 SV3D_p。其中 SV3D_u 基于单个图像输入生成轨道视频,不需要相机调整;SV3D_p 通过适配单个图像和轨道视角扩展了生成能力,允许沿着指定的相机路径创建 3D 视频。
目前,Stable Video 3D 的研究论文已经放出,核心作者有三位。
- 论文地址:https://stability.ai/s/SV3D_report.pdf
- 博客地址:https://stability.ai/news/introducing-stable-video-3d
- Huggingface 地址:https://huggingface.co/stabilityai/sv3d
技术概览
Stable Video 3D 在 3D 生成领域实现重大进步,尤其是在新颖视图生成(novel view synthesis,NVS)方面。
以往的方法通常倾向于解决有限视角和输入不一致的问题,而 Stable Video 3D 能够从任何给定角度提供连贯视图,并能够很好地泛化。因此,该模型不仅增加了姿势可控性,还能确保多个视图中对象外观的一致性,进一步改进了影响真实和准确 3D 生成的关键问题。
如下图所示,与 Stable Zero123、Zero-XL 相比,Stable Video 3D 能够生成细节更强、更忠实于输入图像和多视角更一致的新颖多视图。
此外,Stable Video 3D 利用其多视角一致性来优化 3D 神经辐射场(Neural Radiance Fields,NeRF),以提高直接从新视图生成 3D 网格的质量。
为此,Stability AI 设计了掩码分数蒸馏采样损失,进一步增强了预测视图中未见过区域的 3D 质量。同时为了减轻烘焙照明问题,Stable Video 3D 采用了与 3D 形状和纹理共同优化的解耦照明模型。
下图为使用 Stable Video 3D 模型及其输出时,通过 3D 优化改进后的 3D 网格生成示例。
Stable Video 3D 模型的架构如下图 2 所示,它基于 Stable Video Diffusion 架构构建而成,包含一个具有多个层的 UNet,其中每一层又包含一个带有 Conv3D 层的残差块序列,以及两个带有注意力层(空间和时间)的 transformer 块。
具体流程如下所示:
(i) 删除「fps id」和「motion bucket id」的矢量条件, 原因是它们与 Stable Video 3D 无关;(ii) 条件图像通过 Stable Video Diffusion 的 VAE 编码器嵌入到潜在空间,然后在通向 UNet 的噪声时间步 t 处连接到噪声潜在状态输入 zt;(iii) 条件图像的 CLIPembedding 矩阵被提供给每个 transformer 块的交叉注意力层来充当键和值,而查询成为相应层的特征;(iv) 相机轨迹沿着扩散噪声时间步被馈入到残差块中。相机姿势角度 ei 和 ai 以及噪声时间步 t 首先被嵌入到正弦位置嵌入中,然后将相机姿势嵌入连接在一起进行线性变换并添加到噪声时间步嵌入中,最后被馈入到每个残差块并被添加到该块的输入特征中。
此外,Stability AI 设计了静态轨道和动态轨道来研究相机姿势调整的影响,具体如下图 3 所示。
在静态轨道上,相机采用与条件图像相同的仰角,以等距方位角围绕对象旋转。这样做的缺点是基于调整的仰角,可能无法获得关于对象顶部或底部的任何信息。而在动态轨道上,方位角可以不等距,每个视图的仰角也可以不同。
为了构建动态轨道,Stability AI 对静态轨道采样,向方位角添加小的随机噪声,并向其仰角添加不同频率的正弦曲线的随机加权组合。这样做提供了时间平滑性,并确保相机轨迹沿着与条件图像相同的方位角和仰角循环结束。
实验结果
Stability AI 在未见过的 GSO 和 OmniObject3D 数据集上,评估了静态和动态轨道上的 Stable Video 3D 合成多视图效果。结果如下表 1 至表 4 所示,Stable Video 3D 在新颖多视图合成方面实现了 SOTA 效果。
表 1 和表 3 显示了 Stable Video 3D 与其他模型在静态轨道的结果,表明了即使是无姿势调整的模型 SV3D_u,也比所有先前的方法表现得更好。
消融分析结果表明,SV3D_c 和 SV3D_p 在静态轨道的生成方面优于 SV3D_u,尽管后者专门在静态轨道上进行了训练。
下表 2 和表 4 展示了动态轨道的生成结果,包括姿势调整模型 SV3D_c 和 SV3D_p,后者在所有指标上实现了 SOTA。
下图 6 中的视觉比较结果进一步表明,与以往工作相比,Stable Video 3D 生成的图像细节更强、更忠实于条件图像、多视角更加一致。
更多技术细节和实验结果请参阅原论文。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com